Chapter 9 STM
Reference: https://juliasilge.com/blog/evaluating-stm/ - https://juliasilge.com/blog/sherlock-holmes-stm/ - RPubs - stm_course
9.0.1 Setups
pkgs <- c("LDAvis", "tidyverse", "jiebaR", "igraph", "stm", "wordcloud")
install.packages(pkgs[!pkgs %in% installed.packages()])
library(tidyverse)
library(tidyr)
options(scipen = 999)load("data/s3_watched.rda")
Sys.setlocale(locale="zh_TW.UTF-8")## [1] "zh_TW.UTF-8/zh_TW.UTF-8/zh_TW.UTF-8/C/zh_TW.UTF-8/zh_TW.UTF-8"library(jiebaR)
stopWords <- readRDS("data/stopWords.rds")
segment_not <- c("爸爸", "爸媽", "新手")
watched <- c("爸爸","父親","老公","先生","丈夫","奶爸","寶爸","隊友",
"爹地","爸比","把拔","把鼻","老爸","另一半","拔拔",
"孩子的爸","孩子爸", "爸拔","他爸","她爸","新手爸","版爸",
"板爸","我家男人","當爸的","腦公","阿爸","人父","孩子的爹",
"孩子爹","老爹","外子","拔比","爸鼻","爸把","爸逼","爸咪",
"把爸","拔爸","爹低","帥爸","準爸","小孩爸","親爸","神爸",
"宅爸","瓶餵爸","寶寶的爸","孩的爸","女兒的爸")
reserved <- c("神隊友", "豬隊友", "好隊友", "好先生", "好爸爸", "好老公")
watched <- c(watched, reserved)
watched.str <- paste0(watched, collapse = "|")
reserved <- c("神隊友", "豬隊友", "好隊友", "好先生", "好爸爸", "好老公")
cutter <- worker()
tagger <- worker("tag")
new_user_word(cutter, segment_not) %>% invisible()
new_user_word(cutter, watched) %>% invisible()
new_user_word(tagger, segment_not) %>% invisible()
new_user_word(tagger, watched) %>% invisible()9.0.2 Pre-processing
unnested.df <- s3.watched %>%
filter(str_detect(sentence, "隊友")) %>%
mutate(word = purrr::map(s3, function(x)segment(x, cutter))) %>%
unnest(word) %>%
anti_join(stopWords) %>%
filter(!str_detect(word, "[a-zA-Z0-9]+")) %>%
filter(!is.na(word)) %>%
group_by(word) %>%
filter(n() > 5) %>%
ungroup() %>%
filter(nchar(word) > 1)library(tidytext)
# library(quanteda)
dfm <- unnested.df %>%
count(doc_id, word, sort = TRUE) %>%
cast_dfm(doc_id, word, n) #tidytext9.0.3 STM
Generated topic model can be saved as rda file for furture use
library(stm)
topic_model <- stm(dfm, K = 12, verbose = F)
# save(topic_model, file="output/tm02_s3_k12.rda")
# load("output/tm02_s3_k12.rda")summary(topic_model)## A topic model with 12 topics, 2925 documents and a 3072 word dictionary.## Topic 1 Top Words:
## Highest Prob: 問題, 知道, 媽媽, 發現, 有沒有, 一些, 比較
## FREX: 提籃, 有沒有, 問題, 開車, 解決, 提供, 類似
## Lift: 提籃, 爸比, 保證, 很常, 理論, 輪子, 每晚
## Score: 有沒有, 提籃, 問題, 保證, 發現, 每晚, 知道
## Topic 2 Top Words:
## Highest Prob: 隊友, 大寶, 晚上, 時間, 上班, 回家, 幫忙
## FREX: 大寶, 白天, 上班, 中心, 一打, 晚上, 下班
## Lift: 放學, 清醒, 硬塊, 作月子, 點到, 放電, 加班
## Score: 大寶, 隊友, 中心, 晚上, 白天, 上班, 擠奶
## Topic 3 Top Words:
## Highest Prob: 討論, 反應, 重點, 原因, 味道, 困擾, 冰箱
## FREX: 口味, 附上, 禮盒, 這款, 清潔, 拿來, 親愛
## Lift: 隔離, 戒菸, 口味, 母湯, 巧克力, 乳腺炎, 晚安
## Score: 禮盒, 胃口, 討論, 油飯, 警衛, 附上, 這款
## Topic 4 Top Words:
## Highest Prob: 寶寶, 隊友, 覺得, 一直, 媽媽, 目前, 喜歡
## FREX: 配方, 寶寶, 請問, 名字, 母乳, 喜歡, 奶粉
## Lift: 該不該, 好用, 兩款, 兩難, 亂跑, 貓咪, 名單
## Score: 寶寶, 隊友, 名字, 正向, 推車, 覺得, 意見
## Topic 5 Top Words:
## Highest Prob: 豬隊友, 女兒, 小孩, 媽媽, 半夜, 餵奶, 嬰兒
## FREX: 奶嘴, 豬隊友, 餵奶, 女兒, 訓練, 餵食, 換尿布
## Lift: 起跳, 完奶, 餵食, 搬出來, 代幣, 那次, 奶嘴
## Score: 豬隊友, 女兒, 男性, 奶嘴, 餵奶, 半夜, 小孩
## Topic 6 Top Words:
## Highest Prob: 隊友, 兒子, 一個, 今天, 看到, 我們, 最近
## FREX: 兒子, 使用, 衣服, 過敏, 空氣, 包巾, 消毒
## Lift: 背心, 補習, 地墊, 蓋子, 喝到, 清淨機, 上會
## Score: 隊友, 兒子, 提醒, 使用, 跑腿, 尿布, 過敏
## Topic 7 Top Words:
## Highest Prob: 隊友, 醫生, 我們, 醫師, 診所, 檢查, 一直
## FREX: 診所, 嫂子, 檢查, 報告, 症狀, 感冒, 傳染
## Lift: 鼻塞, 不看, 陳醫師, 傳染, 端菜, 甘蔗, 恢復正常
## Score: 醫生, 醫師, 嫂子, 診所, 隊友, 超音波, 檢查
## Topic 8 Top Words:
## Highest Prob: 婆婆, 老公, 隊友, 幫忙, 婆家, 公婆, 娘家
## FREX: 婆婆, 孫子, 坐月子, 老公, 我媽, 公公, 不在
## Lift: 婆媳, 宴客, 還帶, 很弱, 認生, 孫子, 小嬸
## Score: 婆婆, 老公, 婆家, 公婆, 公公, 坐月子, 隊友
## Topic 9 Top Words:
## Highest Prob: 真的, 隊友, 孩子, 覺得, 好隊友, 我們, 謝謝
## FREX: 憂鬱, 情緒, 好隊友, 先生, 心情, 經濟, 辛苦
## Lift: 性子, 愛的, 變大, 打拼, 道理, 好難, 好先生
## Score: 好隊友, 隊友, 真的, 先生, 情緒, 孩子, 老公
## Topic 10 Top Words:
## Highest Prob: 神隊友, 媽媽, 爸爸, 分享, 一起, 育兒, 希望
## FREX: 神隊友, 課程, 參與, 運動, 回覆, 育兒, 參考
## Lift: 北醫, 場次, 大小事, 哥們, 健身房, 日常, 蒐集
## Score: 神隊友, 爸爸, 育兒, 分享, 原則, 媽媽, 運動
## Topic 11 Top Words:
## Highest Prob: 隊友, 護理, 醫院, 醫生, 陣痛, 真的, 一直
## FREX: 陣痛, 無痛, 痛到, 宮縮, 內診, 催生, 傷口
## Lift: 退貨, 產兆, 單人房, 發明, 縫合, 宮縮, 好痛
## Score: 陣痛, 無痛, 護理, 醫院, 產房, 隊友, 內診
## Topic 12 Top Words:
## Highest Prob: 隊友, 小孩, 覺得, 公婆, 直接, 我們, 不想
## FREX: 小朋友, 小孩, 長輩, 弟弟, 哥哥, 上學, 不爽
## Lift: 班上, 衝康, 老木, 前天, 他媽, 溫和, 薪資
## Score: 小孩, 隊友, 前天, 公婆, 小朋友, 保母, 溝通# print(topic_model)Using wordcloud for visualization often leads to misunderstanding due to the number of letters in the word.
# install.packages("wordcloud")
cloud(topic_model, topic = 7, scale = c(4,.5), family = "Heiti TC Light")
library(igraph)
mod.out.corr <- topicCorr(topic_model)
plot(mod.out.corr)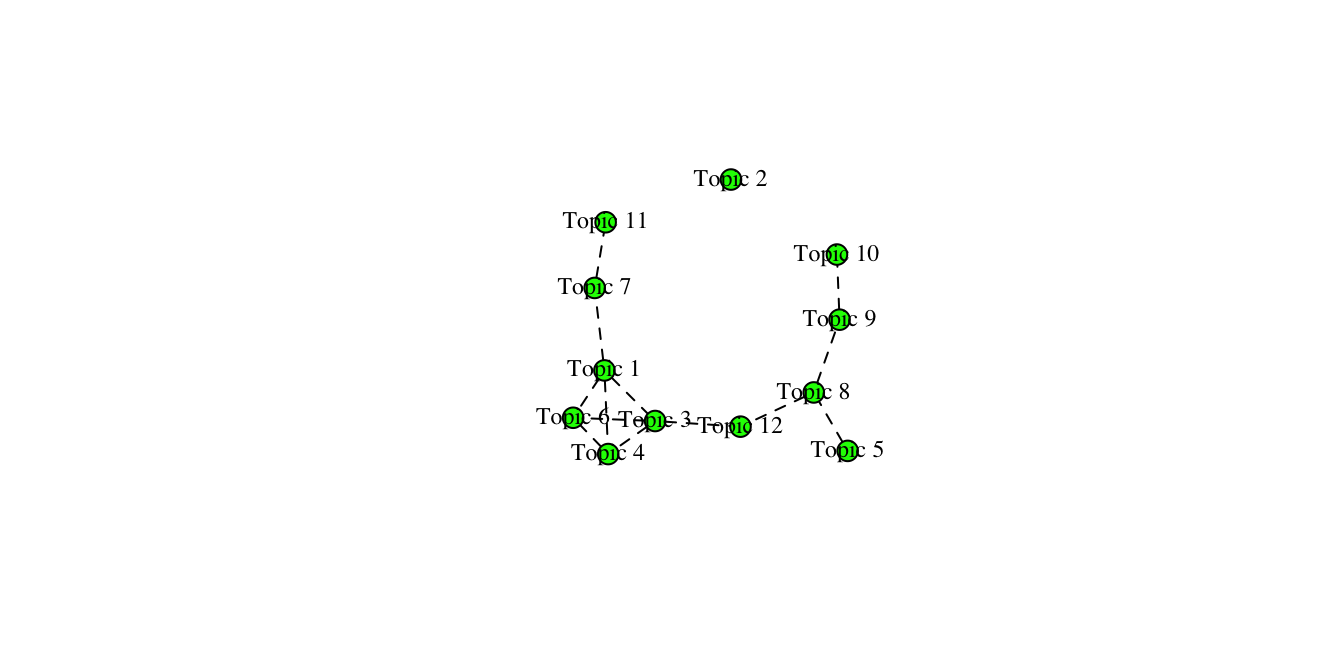
# mod.out.corr9.0.4 LDAvis
See Sievert, C., & Shirley, K. (2014). LDAvis: A method for visualizing and interpreting topics. Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces. Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, Maryland, USA. https://doi.org/10.3115/v1/w14-3110
- saliency(term w) = frequency(w) * [sum_t p(t | w) * log(p(t | w)/p(t))] for topics t; see Chuang et. al (2012)
- relevance(term w | topic t) = λ * p(w | t) + (1 - λ) * p(w | t)/p(w); see Sievert & Shirley (2014). Lift: p(w|t)/p(w) = p(w and t)/(p(w)p(t))
stm.doc <- quanteda::convert(dfm, to = "stm")
toLDAvis(topic_model, stm.doc$documents)9.0.5 Validating
library(furrr)
plan(multiprocess)
many_models <- tibble(K = c(8, 16, 24, 32, 64)) %>%
mutate(topic_model = future_map(K, ~stm(dfm, K = ., verbose = F)))heldout <- make.heldout(dfm)
k_result <- many_models %>%
mutate(exclusivity = map(topic_model, exclusivity),
semantic_coherence = map(topic_model, semanticCoherence, dfm),
eval_heldout = map(topic_model, eval.heldout, heldout$missing),
residual = map(topic_model, checkResiduals, dfm),
bound = map_dbl(topic_model, function(x) max(x$convergence$bound)),
lfact = map_dbl(topic_model, function(x) lfactorial(x$settings$dim$K)),
lbound = bound + lfact,
iterations = map_dbl(topic_model, function(x) length(x$convergence$bound)))
k_result## # A tibble: 5 × 10
## K topic_model exclusivity semantic_coherence eval_heldout residual
## <dbl> <list> <list> <list> <list> <list>
## 1 8 <STM> <dbl [8]> <dbl [8]> <named list [4]> <named list>
## 2 16 <STM> <dbl [16]> <dbl [16]> <named list [4]> <named list>
## 3 24 <STM> <dbl [24]> <dbl [24]> <named list [4]> <named list>
## 4 32 <STM> <dbl [32]> <dbl [32]> <named list [4]> <named list>
## 5 64 <STM> <dbl [64]> <dbl [64]> <named list [4]> <named list>
## # … with 4 more variables: bound <dbl>, lfact <dbl>, lbound <dbl>,
## # iterations <dbl>k_result %>%
transmute(K,
`Lower bound` = lbound,
Residuals = map_dbl(residual, "dispersion"),
`Semantic coherence` = map_dbl(semantic_coherence, mean),
`Held-out likelihood` = map_dbl(eval_heldout, "expected.heldout")) %>%
gather(Metric, Value, -K) %>%
ggplot(aes(K, Value, color = Metric)) +
geom_line(size = 1.5, alpha = 0.7, show.legend = FALSE) +
facet_wrap(~Metric, scales = "free_y") +
labs(x = "K (number of topics)",
y = NULL,
title = "Model diagnostics by number of topics",
subtitle = "These diagnostics indicate that a good number of topics would be around 60")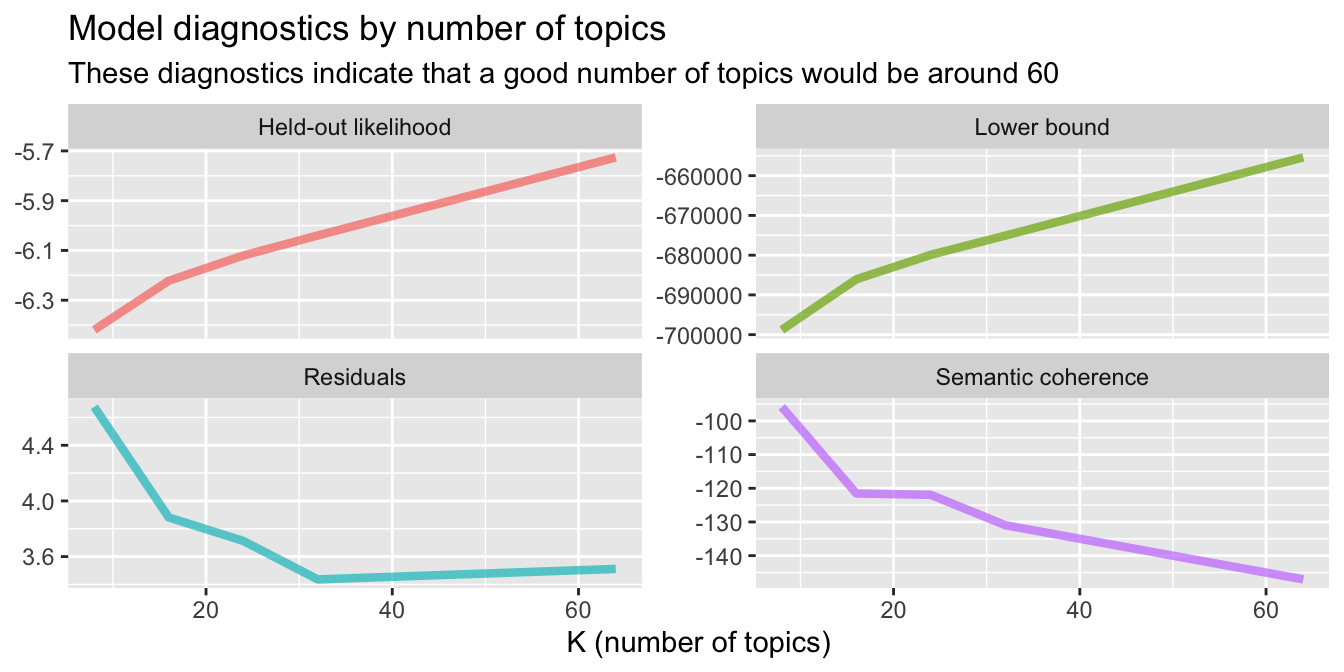
k_result %>%
select(K, exclusivity, semantic_coherence) %>%
filter(K %in% c(16, 24, 64)) %>%
unnest() %>%
mutate(K = as.factor(K)) %>%
ggplot(aes(semantic_coherence, exclusivity, color = K)) +
geom_point(size = 2, alpha = 0.7) +
labs(x = "Semantic coherence",
y = "Exclusivity",
title = "Comparing exclusivity and semantic coherence",
subtitle = "Models with fewer topics have higher semantic coherence for more topics, but lower exclusivity")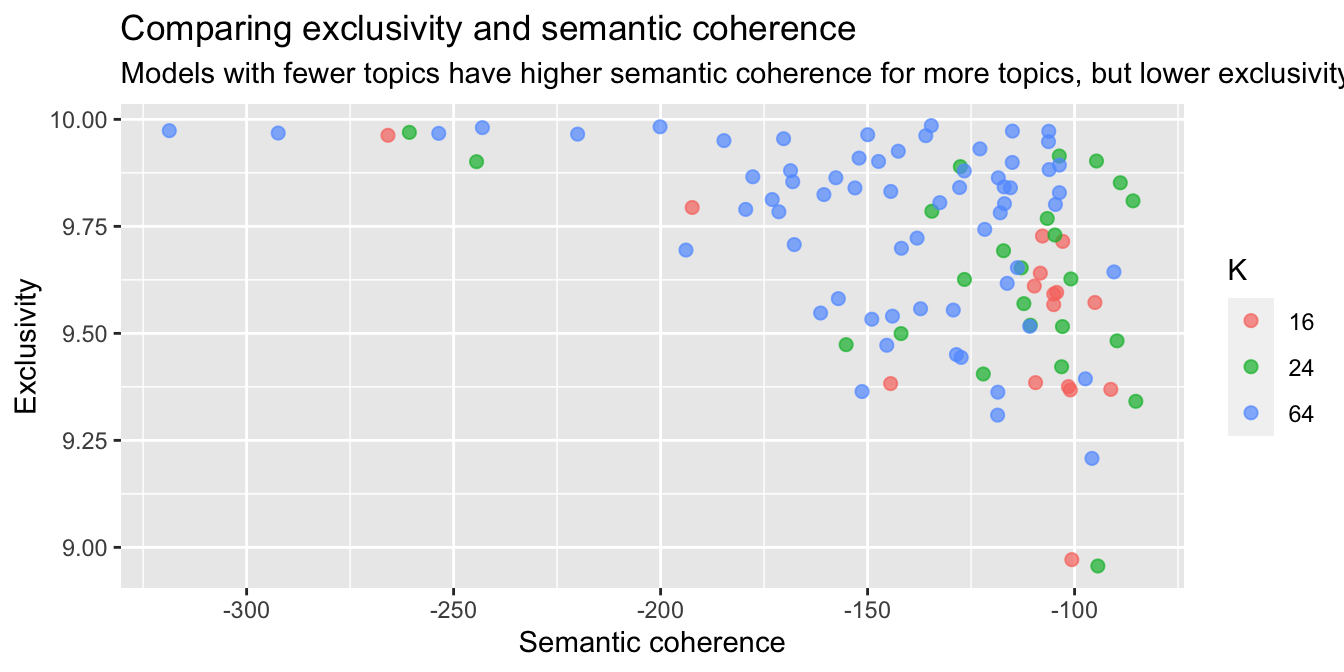
9.0.6 Exploring model
td_beta <- tidy(topic_model)
td_beta %>% filter(topic==1) %>% arrange(-beta) %>% head(10)## # A tibble: 10 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 問題 0.0626
## 2 1 知道 0.0534
## 3 1 媽媽 0.0415
## 4 1 發現 0.0333
## 5 1 有沒有 0.0316
## 6 1 一些 0.0265
## 7 1 比較 0.0261
## 8 1 幾天 0.0221
## 9 1 狀況 0.0214
## 10 1 有人 0.0197td_gamma <- tidy(topic_model, matrix = "gamma", document_names = rownames(dfm))
td_gamma## # A tibble: 35,100 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 M.1476742346.A.F57 1 0.00281
## 2 M.1563679368.A.C2B 1 0.0564
## 3 M.1600923114.A.8F4 1 0.00666
## 4 M.1488086113.A.85C 1 0.00301
## 5 M.1533754307.A.070 1 0.0127
## 6 M.1549687071.A.D3A 1 0.116
## 7 M.1500566217.A.CE9 1 0.00351
## 8 M.1554769984.A.A64 1 0.00542
## 9 M.1593828875.A.DB9 1 0.0616
## 10 M.1554558794.A.4AA 1 0.00811
## # … with 35,090 more rowstop_terms <- td_beta %>%
arrange(beta) %>%
group_by(topic) %>%
top_n(6, beta) %>%
arrange(-beta) %>%
select(topic, term) %>%
summarise(terms = list(term)) %>%
mutate(terms = map(terms, paste, collapse = ", ")) %>%
unnest()
gamma_terms <- td_gamma %>%
group_by(topic) %>%
summarise(gamma = mean(gamma)) %>%
arrange(desc(gamma)) %>%
left_join(top_terms, by = "topic") %>%
mutate(topic = paste0("Topic ", topic),
topic = reorder(topic, gamma))
gamma_terms %>%
ggplot(aes(topic, gamma, label = terms, fill = topic)) +
geom_col(show.legend = FALSE) +
geom_text(hjust = 0, nudge_y = 0.0005, size = 3,
family = "Heiti TC Light") +
coord_flip() +
scale_y_continuous(expand = c(0,0),
limits = c(0, max(gamma_terms$gamma)+0.1),
labels = scales::percent_format()) +
theme(plot.title = element_text(size = 16,
family="Heiti TC Light"),
plot.subtitle = element_text(size = 13)) +
theme_minimal()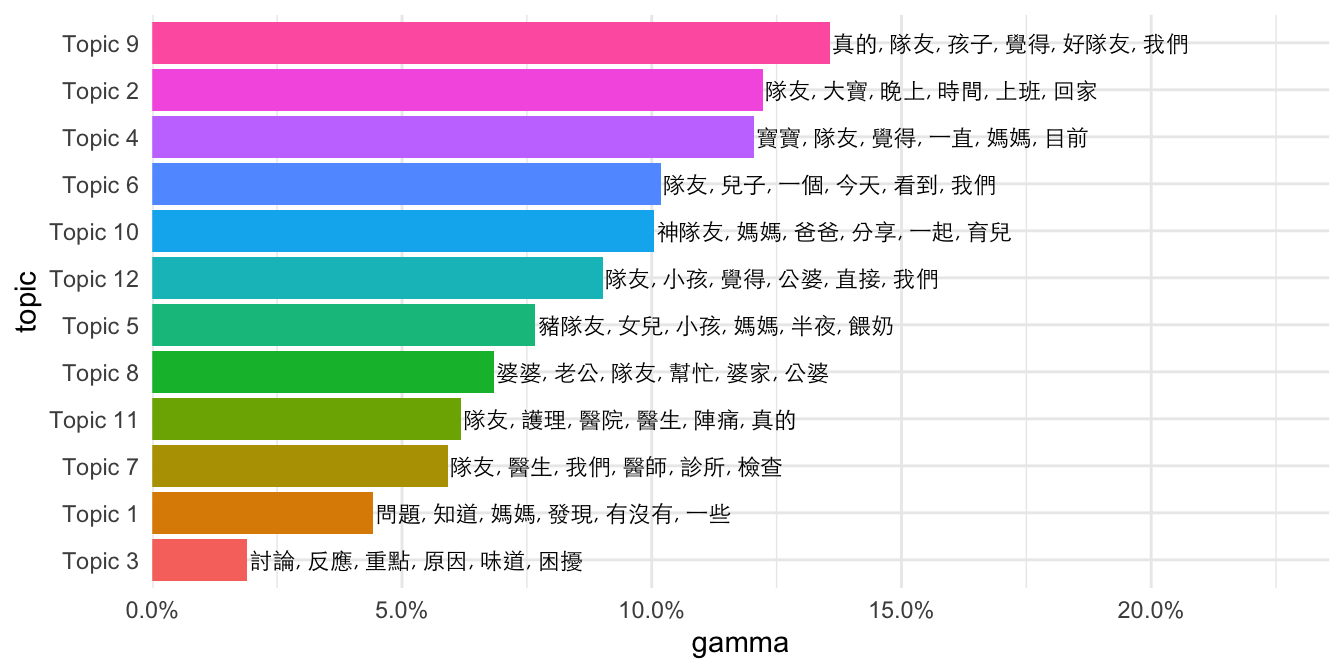
gamma_terms %>%
select(topic, gamma, terms) ## # A tibble: 12 × 3
## topic gamma terms
## <fct> <dbl> <chr>
## 1 Topic 9 0.136 真的, 隊友, 孩子, 覺得, 好隊友, 我們
## 2 Topic 2 0.122 隊友, 大寶, 晚上, 時間, 上班, 回家
## 3 Topic 4 0.120 寶寶, 隊友, 覺得, 一直, 媽媽, 目前
## 4 Topic 6 0.102 隊友, 兒子, 一個, 今天, 看到, 我們
## 5 Topic 10 0.100 神隊友, 媽媽, 爸爸, 分享, 一起, 育兒
## 6 Topic 12 0.0902 隊友, 小孩, 覺得, 公婆, 直接, 我們
## 7 Topic 5 0.0767 豬隊友, 女兒, 小孩, 媽媽, 半夜, 餵奶
## 8 Topic 8 0.0684 婆婆, 老公, 隊友, 幫忙, 婆家, 公婆
## 9 Topic 11 0.0619 隊友, 護理, 醫院, 醫生, 陣痛, 真的
## 10 Topic 7 0.0591 隊友, 醫生, 我們, 醫師, 診所, 檢查
## 11 Topic 1 0.0442 問題, 知道, 媽媽, 發現, 有沒有, 一些
## 12 Topic 3 0.0191 討論, 反應, 重點, 原因, 味道, 困擾