TM06 Clustering#
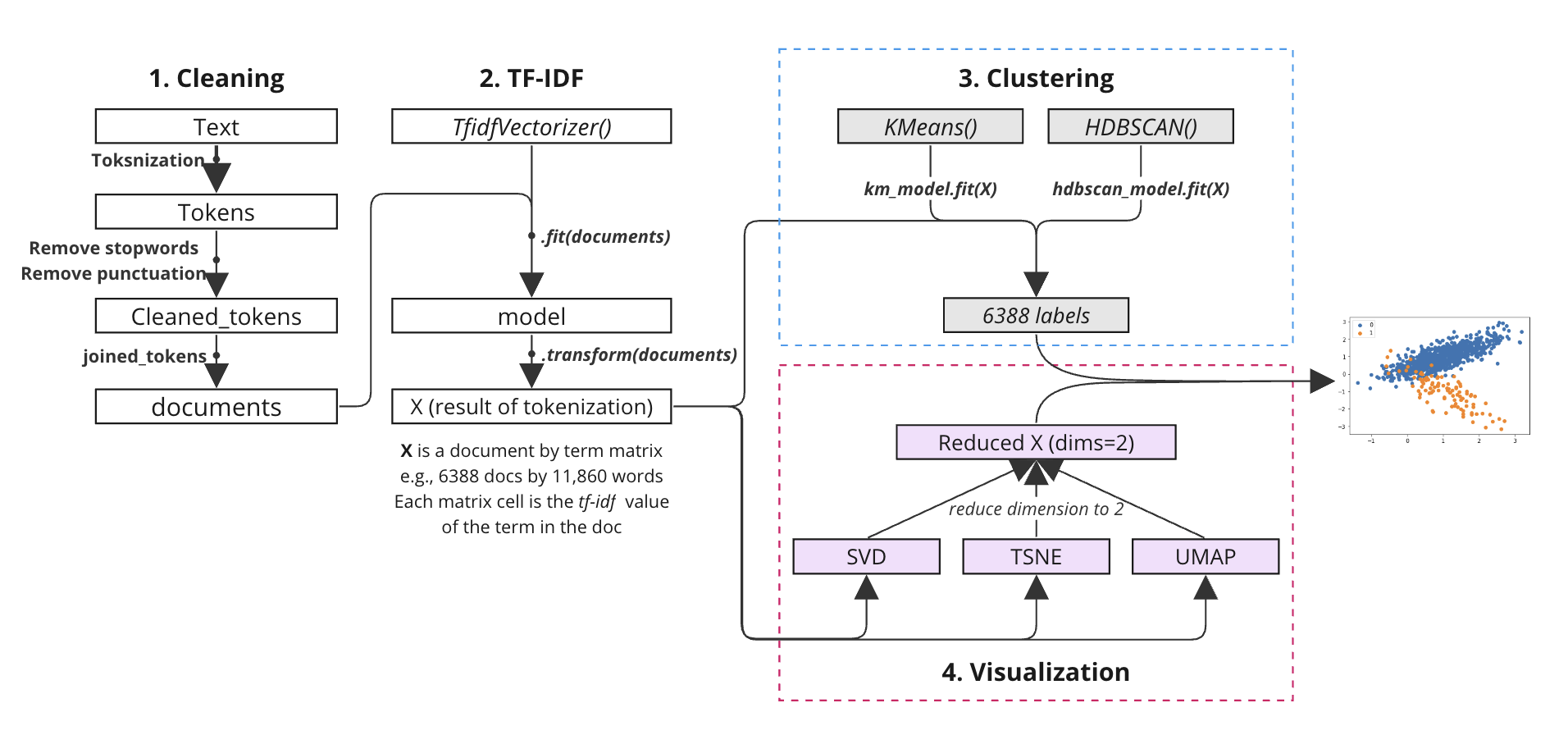
[Cleaning] Prepare data#
# Can download the file from ...
# !wget https://raw.githubusercontent.com/p4css/py4css/main/data/sentiment.csv -O sentiment.csv
# OR, alternatively, create also a data/ sub-directory by this way
# !wget https://raw.githubusercontent.com/p4css/py4css/main/data/sentiment.csv -P data/
import pandas as pd
df = pd.read_csv('data/sentiment.csv')
/Users/jirlong/opt/anaconda3/lib/python3.9/site-packages/pandas/core/computation/expressions.py:21: UserWarning: Pandas requires version '2.8.4' or newer of 'numexpr' (version '2.8.1' currently installed).
from pandas.core.computation.check import NUMEXPR_INSTALLED
/Users/jirlong/opt/anaconda3/lib/python3.9/site-packages/pandas/core/arrays/masked.py:60: UserWarning: Pandas requires version '1.3.6' or newer of 'bottleneck' (version '1.3.4' currently installed).
from pandas.core import (
Chinese Tokenization with jieba#
# !pip install jieba
import jieba
df['token_text'] = df['text'].apply(lambda x:list(jieba.cut(x)))
df.head(10)
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/j3/p4x0mssx55nd8dn903h5wdb00000gn/T/jieba.cache
Loading model cost 0.279 seconds.
Prefix dict has been built successfully.
| tag | text | token_text | |
|---|---|---|---|
| 0 | P | 店家很給力,快遞也是相當快,第三次光顧啦 | [店家, 很, 給力, ,, 快遞, 也, 是, 相當快, ,, 第三次, 光顧, 啦] |
| 1 | N | 這樣的配置用Vista系統還是有點卡。 指紋收集器。 沒送原裝滑鼠還需要自己買,不太好。 | [這樣, 的, 配置, 用, Vista, 系統, 還是, 有點, 卡, 。, , 指紋,... |
| 2 | P | 不錯,在同等檔次酒店中應該是值得推薦的! | [不錯, ,, 在, 同等, 檔次, 酒店, 中應, 該, 是, 值得, 推薦, 的, !] |
| 3 | N | 哎! 不會是蒙牛乾的吧 嚴懲真凶! | [哎, !, , 不會, 是, 蒙牛, 乾, 的, 吧, , 嚴懲, 真凶, !] |
| 4 | N | 空尤其是三立電視臺女主播做的序尤其無趣像是硬湊那麼多字 | [空, 尤其, 是, 三立, 電視, 臺, 女主播, 做, 的, 序, 尤其, 無趣, 像是... |
| 5 | N | 明明買了6本書,只到了3本,也沒有說是什麼原因,以後怎麼信的過??????????? | [明明, 買, 了, 6, 本書, ,, 只到, 了, 3, 本, ,, 也, 沒, 有, ... |
| 6 | P | 看了一下感覺還可以 | [看, 了, 一下, 感覺還, 可以] |
| 7 | P | 散熱還不錯,玩遊戲cpu溫度和硬碟溫度都在56以下, 速度很好,顯示卡也不錯 | [散熱, 還不錯, ,, 玩遊戲, cpu, 溫度, 和, 硬碟, 溫度, 都, 在, 56... |
| 8 | P | 外觀好看,白色的自己貼紙也方便,vista執行起來速度也還不錯.屬於主流配置了。一般用用可以的 | [外觀, 好看, ,, 白色, 的, 自己, 貼紙, 也, 方便, ,, vista, 執行... |
| 9 | N | 水超級小 用的時候還要先修理一下花灑 售後還說是水壓問題 說本來標配都是這樣還要自己重新換一個 | [水超級, 小, , 用, 的, 時候, 還要, 先, 修理, 一下, 花灑, , 售後... |
Removing Punctuations and stopwords#
# !wget https://raw.githubusercontent.com/p4css/py4css/main/data/sentiment.csv -O stopwords_zh-tw.txt
# !wget https://raw.githubusercontent.com/p4css/py4css/main/data/sentiment.csv -P data/
with open("data/stopwords_zh-tw.txt", encoding="utf-8") as fin:
stopwords = fin.read().split("\n")[1:]
print("stop words: ", stopwords[:100])
print(len(stopwords))
def remove_stopWords(words):
out = []
for word in words:
if word not in stopwords:
out.append(word)
return out
import unicodedata # for removing Chinese puctuation
def remove_punc_by_unicode(words):
out = []
for word in words:
if word != " " and not unicodedata.category(word[0]).startswith('P'):
out.append(word)
return out
df['cleaned'] = df['token_text'].apply(remove_stopWords)
df['cleaned'] = df['cleaned'].apply(remove_punc_by_unicode)
df.head()
stop words: ['?', '、', '。', '“', '”', '《', '》', '!', '「', '」', '『', '』', ',', ':', ';', '?', '人民', '末##末', '啊', '阿', '哎', '哎呀', '哎喲', '唉', '我', '我們', '按', '按照', '依照', '吧', '吧噠', '把', '罷了', '被', '本', '本著', '比', '比方', '比如', '鄙人', '彼', '彼此', '邊', '別', '別的', '別說', '並', '並且', '不比', '不成', '不單', '不但', '不獨', '不管', '不光', '不過', '不僅', '不拘', '不論', '不怕', '不然', '不如', '不特', '不惟', '不問', '不只', '朝', '朝著', '趁', '趁著', '乘', '沖', '除', '除此之外', '除非', '除了', '此', '此間', '此外', '從', '從而', '打', '待', '但', '但是', '當', '當著', '到', '得', '的', '的話', '等', '等等', '地', '第', '叮咚', '對', '對於', '多', '多少']
1212
| tag | text | token_text | cleaned | |
|---|---|---|---|---|
| 0 | P | 店家很給力,快遞也是相當快,第三次光顧啦 | [店家, 很, 給力, ,, 快遞, 也, 是, 相當快, ,, 第三次, 光顧, 啦] | [店家, 給力, 快遞, 相當快, 第三次, 光顧] |
| 1 | N | 這樣的配置用Vista系統還是有點卡。 指紋收集器。 沒送原裝滑鼠還需要自己買,不太好。 | [這樣, 的, 配置, 用, Vista, 系統, 還是, 有點, 卡, 。, , 指紋,... | [配置, Vista, 系統, 有點, 卡, 指紋, 收集器, 沒送, 原裝, 滑鼠, 需要... |
| 2 | P | 不錯,在同等檔次酒店中應該是值得推薦的! | [不錯, ,, 在, 同等, 檔次, 酒店, 中應, 該, 是, 值得, 推薦, 的, !] | [不錯, 同等, 檔次, 酒店, 中應, 值得, 推薦] |
| 3 | N | 哎! 不會是蒙牛乾的吧 嚴懲真凶! | [哎, !, , 不會, 是, 蒙牛, 乾, 的, 吧, , 嚴懲, 真凶, !] | [蒙牛, 乾, 嚴懲, 真凶] |
| 4 | N | 空尤其是三立電視臺女主播做的序尤其無趣像是硬湊那麼多字 | [空, 尤其, 是, 三立, 電視, 臺, 女主播, 做, 的, 序, 尤其, 無趣, 像是... | [空, 尤其, 三立, 電視, 臺, 女主播, 做, 序, 尤其, 無趣, 像是, 硬, 湊... |
Feature selection (TF-IDF)#
tfidf vectorization#
https://towardsdatascience.com/clustering-documents-with-python-97314ad6a78d
https://blog.csdn.net/blmoistawinde/article/details/80816179
"""
Each document is a list of words. For each documnet,
join list of string to a string seperated by space
Caoncatenate all documents to a list
"""
documents = [" ".join(doc) for doc in df['cleaned']]
documents[:5]
['店家 給力 快遞 相當快 第三次 光顧',
'配置 Vista 系統 有點 卡 指紋 收集器 沒送 原裝 滑鼠 需要 買 不太好',
'不錯 同等 檔次 酒店 中應 值得 推薦',
'蒙牛 乾 嚴懲 真凶',
'空 尤其 三立 電視 臺 女主播 做 序 尤其 無趣 像是 硬 湊 多字']
Method 1.#
.fit_transform() fit and transform the tfidf vectorizer on the corpus to get the feature vectors.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
ngram_range = (1, 2),
max_df =0.2,
token_pattern = r"(?u)\b\w+\b",
use_idf = True
)
X = vectorizer.fit_transform(documents)
len(documents)
6388
Method 2.#
Model 1: Original tfidf
Model 2: Define how to tokenize a string, the pattern offen appears in English tokenziation
Model 3: 有時我們需要過濾掉一些無意義的詞語。為此,可以使用
max_df/min_df這樣的參數,其值可以設為 [0.0, 1.0] 範圍內的浮點數或正整數(預設值為1.0)。當設置為浮點數時,這些參數將過濾掉出現在超過指定百分比(max_df)或低於指定百分比(min_df)的句子中的詞語;設置為正整數時,則過濾掉出現在超過特定數量的句子中的詞語。這樣可以幫助我們濾除出現過於頻繁的無意義詞語。例如,在給定的例子中,「我」這個詞被過濾掉,即使在文學上它的重複使用可能具有重要性。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_df=0.01, stop_words=stopwords) # initialize tf-idf
tfidf_model = tfidf.fit(documents) # learn vocabulary and idf from training set
X = tfidf_model.transform(documents) # transform the test set into tf-idf
X_dense = X.todense()
print(X_dense.shape)
print(X_dense[:20, :20])
(6388, 11860)
[[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0.34691387 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. ]]
"""
Model 1: Default setting
"""
tfidf_model = TfidfVectorizer().fit(documents)
sparse_result = tfidf_model.transform(documents)
# print(sparse_result)
print("Number of features in model 1: ", len(tfidf_model.vocabulary_))
"""
Model 2:
"""
tfidf_model2 = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b").fit(documents)
print("Number of features in model 2: ", len(tfidf_model2.vocabulary_))
tfidf_model3 = TfidfVectorizer(max_df=0.05).fit(documents)
print("Number of features in model 3: ", len(tfidf_model3.vocabulary_))
tfidf_model4 = TfidfVectorizer(
max_df=0.01,
# token_pattern=r"(?u)\b\w+\b",
# max_features = 2000,
stop_words=stopwords).fit(documents)
print("Number of features in model 4: ", len(tfidf_model4.vocabulary_))
words = ['給力', '不錯', '不太好', '相當快', '無趣', '還不錯']
word_dict = {w:i for i, w in enumerate(words)}
# print(word_dict)
tfidf_model5 = TfidfVectorizer(
token_pattern=r"(?u)\b\w+\b",
vocabulary={"我":0, "呀":1,"!":2}).fit(documents)
print(tfidf_model5.vocabulary_)
tfidf_model6 = TfidfVectorizer(
ngram_range=(1,2),
max_df=0.01).fit(documents)
print("Number of features in model 6: ", len(tfidf_model6.vocabulary_))
Number of features in model 1: 11964
Number of features in model 2: 13060
Number of features in model 3: 11959
Number of features in model 4: 11860
{'我': 0, '呀': 1, '!': 2}
Number of features in model 6: 48269
transform(): Step 2 of the method 2#
X is a document by term matrix (e.g., 6388 docs by 11,860 words). Each matrix cell is the tf-idf value of the term in the doc.
X = tfidf_model4.transform(documents)
display(X.shape)
X
(6388, 11860)
<6388x11860 sparse matrix of type '<class 'numpy.float64'>'
with 34416 stored elements in Compressed Sparse Row format>
Clustering#
we have a 6388 (docs) x 11860 (terms) matrix. Each raw is the presentation of each document. It is to say each docs is represented by a vector of 11860 terms.
Now we can compare similarities among any pair of documents.
Evaluation for selecting the number of clusters (k)#
The KMeans algorithm clusters data by trying to separate samples in n groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares (https://scikit-learn.org/stable/modules/clustering.html#k-means).
The weak point of KMeans is that we need to decide the number of clusters (k) before we start clustering. There are several ways to evaluate the number of clusters (k) we should use. Here we use the elbow method Above.
You can take a look at the next cell of code to view how to cluster the documents into k clusters before we decide the number of clusters (k).
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
Sum_of_squared_distances = []
# Select K
K = range(2,20)
for k in K:
km = KMeans(n_clusters=k, max_iter=200, n_init=10)
km = km.fit(X)
plt.plot(K, Sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [9], in <cell line: 12>()
8 km = KMeans(n_clusters=k, max_iter=200, n_init=10)
9 km = km.fit(X)
---> 12 plt.plot(K, Sum_of_squared_distances, 'bx-')
13 plt.xlabel('k')
14 plt.ylabel('Sum_of_squared_distances')
File ~/opt/anaconda3/lib/python3.9/site-packages/matplotlib/pyplot.py:2757, in plot(scalex, scaley, data, *args, **kwargs)
2755 @_copy_docstring_and_deprecators(Axes.plot)
2756 def plot(*args, scalex=True, scaley=True, data=None, **kwargs):
-> 2757 return gca().plot(
2758 *args, scalex=scalex, scaley=scaley,
2759 **({"data": data} if data is not None else {}), **kwargs)
File ~/opt/anaconda3/lib/python3.9/site-packages/matplotlib/axes/_axes.py:1632, in Axes.plot(self, scalex, scaley, data, *args, **kwargs)
1390 """
1391 Plot y versus x as lines and/or markers.
1392
(...)
1629 (``'green'``) or hex strings (``'#008000'``).
1630 """
1631 kwargs = cbook.normalize_kwargs(kwargs, mlines.Line2D)
-> 1632 lines = [*self._get_lines(*args, data=data, **kwargs)]
1633 for line in lines:
1634 self.add_line(line)
File ~/opt/anaconda3/lib/python3.9/site-packages/matplotlib/axes/_base.py:312, in _process_plot_var_args.__call__(self, data, *args, **kwargs)
310 this += args[0],
311 args = args[1:]
--> 312 yield from self._plot_args(this, kwargs)
File ~/opt/anaconda3/lib/python3.9/site-packages/matplotlib/axes/_base.py:498, in _process_plot_var_args._plot_args(self, tup, kwargs, return_kwargs)
495 self.axes.yaxis.update_units(y)
497 if x.shape[0] != y.shape[0]:
--> 498 raise ValueError(f"x and y must have same first dimension, but "
499 f"have shapes {x.shape} and {y.shape}")
500 if x.ndim > 2 or y.ndim > 2:
501 raise ValueError(f"x and y can be no greater than 2D, but have "
502 f"shapes {x.shape} and {y.shape}")
ValueError: x and y must have same first dimension, but have shapes (18,) and (0,)

Clustering by KMeans#
After we decide the number of clusters (k), we can start clustering the documents by KMeans.
The params of KMeans:
n_clusters: the number of clusters (k)init: the method for initializationmax_iter: the maximum number of iterationsn_init: the number of times the algorithm will be run with different centroid seeds. The final results will be the best output of n_init consecutive runs in terms of inertia.
The result of KMeans will be a list of labels model.labels_. Each label represents the cluster number of the corresponding document.
from sklearn.cluster import KMeans
true_k = 16
model = KMeans(
n_clusters = true_k,
init = 'k-means++',
max_iter = 200,
n_init = 10)
model.fit(X)
labels=model.labels_
df['cluster'] = labels
display(df.head())
| tag | text | token_text | cleaned | cluster | |
|---|---|---|---|---|---|
| 0 | P | 店家很給力,快遞也是相當快,第三次光顧啦 | [店家, 很, 給力, ,, 快遞, 也, 是, 相當快, ,, 第三次, 光顧, 啦] | [店家, 給力, 快遞, 相當快, 第三次, 光顧] | 3 |
| 1 | N | 這樣的配置用Vista系統還是有點卡。 指紋收集器。 沒送原裝滑鼠還需要自己買,不太好。 | [這樣, 的, 配置, 用, Vista, 系統, 還是, 有點, 卡, 。, , 指紋,... | [配置, Vista, 系統, 有點, 卡, 指紋, 收集器, 沒送, 原裝, 滑鼠, 需要... | 13 |
| 2 | P | 不錯,在同等檔次酒店中應該是值得推薦的! | [不錯, ,, 在, 同等, 檔次, 酒店, 中應, 該, 是, 值得, 推薦, 的, !] | [不錯, 同等, 檔次, 酒店, 中應, 值得, 推薦] | 3 |
| 3 | N | 哎! 不會是蒙牛乾的吧 嚴懲真凶! | [哎, !, , 不會, 是, 蒙牛, 乾, 的, 吧, , 嚴懲, 真凶, !] | [蒙牛, 乾, 嚴懲, 真凶] | 3 |
| 4 | N | 空尤其是三立電視臺女主播做的序尤其無趣像是硬湊那麼多字 | [空, 尤其, 是, 三立, 電視, 臺, 女主播, 做, 的, 序, 尤其, 無趣, 像是... | [空, 尤其, 三立, 電視, 臺, 女主播, 做, 序, 尤其, 無趣, 像是, 硬, 湊... | 3 |
Clustering by HDBSCAN#
https://hdbscan.readthedocs.io/en/latest/comparing_clustering_algorithms.html
HDBSCAN is a clustering algorithm developed by Campello, Moulavi, and Sander. It extends DBSCAN by converting it into a hierarchical clustering algorithm, and then using a technique to extract a flat clustering based in the stability of clusters. This allows HDBSCAN to find clusters of varying densities (unlike DBSCAN), and be more robust to parameter selection.
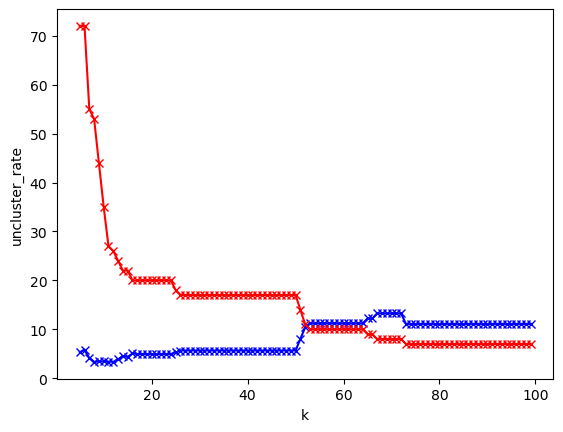
Evaluating param: min_cluster_size#
Before we start clustering, we need to decide the value of min_cluster_size. The value of min_cluster_size is the minimum number of documents in a cluster. If the number of documents in a cluster is less than min_cluster_size, the cluster will be considered as noise.
Here we use two criteria to evaluate the value of min_cluster_size:
The number of clusters
n_clustersThe percentage of noise (the number of documents in noise / the number of documents):
unclustered_ratio
# !pip install hdbscan
from collections import Counter
import hdbscan
import matplotlib.pyplot as plt
unclustered_ratio = []
n_clusters = []
K = range(5, 100)
for k in K:
cluster = hdbscan.HDBSCAN(
min_cluster_size=k,
metric='euclidean',
cluster_selection_method='eom').fit(X)
cluster_counter = Counter(list(cluster.labels_))
unclustered_ratio.append(cluster_counter[-1]/len(documents)*100)
n_clusters.append(len(cluster_counter)-1)
plt.plot(K, unclustered_ratio, 'bx-')
plt.plot(K, n_clusters, 'rx-')
plt.xlabel('k')
plt.ylabel('uncluster_rate')
plt.show()
plt.plot(K, unclustered_ratio, 'bx-')
plt.plot(K, n_clusters, 'rx-')
plt.xlabel('k')
plt.ylabel('cluster_rate')
plt.axvline(x=16, color='r', linestyle='--')
plt.show()
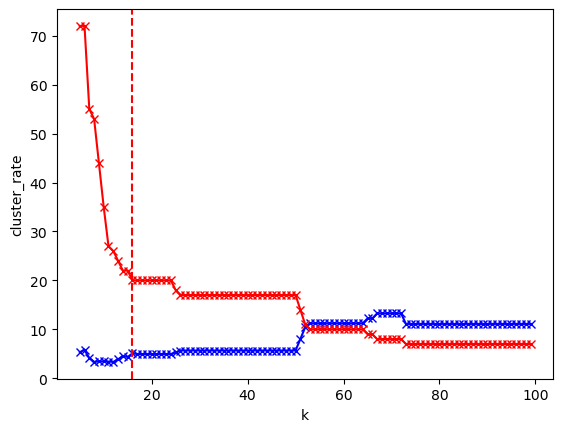
# !pip install hdbscan
import hdbscan
cluster = hdbscan.HDBSCAN(
min_cluster_size=16,
metric='euclidean', # default: 'euclidean', alternative: 'cosine'
cluster_selection_method='eom').fit(X) # default: 'eom', alternative: 'leaf'
print(f"Ratio of unclustered documents: {cluster_counter[-1]/len(documents):.2%}", )
print("Number of clusters: ", len(set(cluster.labels_))-1)
Ratio of unclustered documents: 11.10%
Number of clusters: 20
from collections import Counter
df['cluster'] = list(cluster.labels_)
print(df.columns)
print(len(Counter(df['cluster'])))
print(Counter(df['cluster']))
Index(['tag', 'text', 'token_text', 'cleaned', 'cluster'], dtype='object')
21
Counter({2: 2916, 12: 1098, 8: 677, -1: 325, 14: 271, 10: 180, 18: 170, 5: 130, 13: 67, 17: 67, 15: 64, 0: 52, 7: 51, 4: 51, 3: 51, 11: 50, 9: 50, 6: 50, 19: 24, 1: 24, 16: 20})
df.head()
| tag | text | token_text | cleaned | cluster | |
|---|---|---|---|---|---|
| 0 | P | 店家很給力,快遞也是相當快,第三次光顧啦 | [店家, 很, 給力, ,, 快遞, 也, 是, 相當快, ,, 第三次, 光顧, 啦] | [店家, 給力, 快遞, 相當快, 第三次, 光顧] | -1 |
| 1 | N | 這樣的配置用Vista系統還是有點卡。 指紋收集器。 沒送原裝滑鼠還需要自己買,不太好。 | [這樣, 的, 配置, 用, Vista, 系統, 還是, 有點, 卡, 。, , 指紋,... | [配置, Vista, 系統, 有點, 卡, 指紋, 收集器, 沒送, 原裝, 滑鼠, 需要... | 16 |
| 2 | P | 不錯,在同等檔次酒店中應該是值得推薦的! | [不錯, ,, 在, 同等, 檔次, 酒店, 中應, 該, 是, 值得, 推薦, 的, !] | [不錯, 同等, 檔次, 酒店, 中應, 值得, 推薦] | 16 |
| 3 | N | 哎! 不會是蒙牛乾的吧 嚴懲真凶! | [哎, !, , 不會, 是, 蒙牛, 乾, 的, 吧, , 嚴懲, 真凶, !] | [蒙牛, 乾, 嚴懲, 真凶] | -1 |
| 4 | N | 空尤其是三立電視臺女主播做的序尤其無趣像是硬湊那麼多字 | [空, 尤其, 是, 三立, 電視, 臺, 女主播, 做, 的, 序, 尤其, 無趣, 像是... | [空, 尤其, 三立, 電視, 臺, 女主播, 做, 序, 尤其, 無趣, 像是, 硬, 湊... | -1 |
Visualizing Overall Patterns#
After performing clustering (whether using KMeans or HDBSCAN), we now have labels for each document. Our next step is to create a scatter plot to visualize these documents. Documents with different labels will be represented with different colors.
V1. Document Distribution by dimension reduction#
We now have a 6388 (docs) x 11860 (terms) matrix. Each raw is the presentation of each document. It is to say each docs is represented by a vector of 11860 terms. It is hard to visualize the documents in a 11860-dimensional space. Therefore, we need to reduce the dimension of the documents.
Dimension reduction by SVD#
Here we use the SVD (Singular Value Decomposition) to reduce the dimension of the documents. The SVD is a dimension reduction method. It can reduce the dimension of the documents while keeping the variance of the documents.
We hope to reduce the dimension of the documents to 2 dimensions so that we can visualize the documents in a 2-dimensional space. The SVD can help us to reduce the dimension of the documents to 2 dimensions.
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=2, n_iter=7, random_state=42)
points_svd = svd.fit_transform(X)
points_svd[:10]
array([[ 0.05231804, 0.02824435],
[ 0.04636166, -0.04329032],
[ 0.01193301, -0.00811522],
[ 0.00016142, -0.00013531],
[ 0.01459432, -0.01152482],
[ 0.01037917, -0.01004575],
[ 0.00133032, -0.00150374],
[ 0.02300426, -0.02150665],
[ 0.02293862, -0.02232616],
[ 0.02299304, -0.01331872]])
Reduction using TSNE#
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,
random_state=0,
init='random',)
points_tsne = tsne.fit_transform(X)
points_tsne[:10].shape
(10, 2)
points_tsne.shape
(6388, 2)
Reduction using UMAP#
import umap
points_umap = umap.UMAP(
n_neighbors = 16,
n_components = 2,
metric='cosine').fit_transform(X)
Visualization by matplotlib#
import matplotlib.pyplot as plt
import numpy as np
def plot_scatter(points):
plt.figure(figsize=(24, 24), dpi=300)
labels = list(cluster.labels_)
# Separating x and y coordinates
x_values = [point[0] for point in points]
y_values = [point[1] for point in points]
cmap = plt.cm.get_cmap('viridis', len(set(labels)))
print(len(set(labels)))
# Create scatter plot
scatter = plt.scatter(x_values, y_values, c=labels, cmap=cmap, alpha=0.5)
plt.colorbar(scatter)
# plt.scatter(x_values, y_values, c=labels)
# Add labels and title (optional)
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.title('Scatter Plot Colored by Labels')
# Show plot
plt.show()
display(plot_scatter(points_svd))
display(plot_scatter(points_tsne))
display(plot_scatter(points_umap))
/var/folders/j3/p4x0mssx55nd8dn903h5wdb00000gn/T/ipykernel_98104/1416105121.py:12: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed two minor releases later. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap(obj)`` instead.
cmap = plt.cm.get_cmap('viridis', len(set(labels)))
23
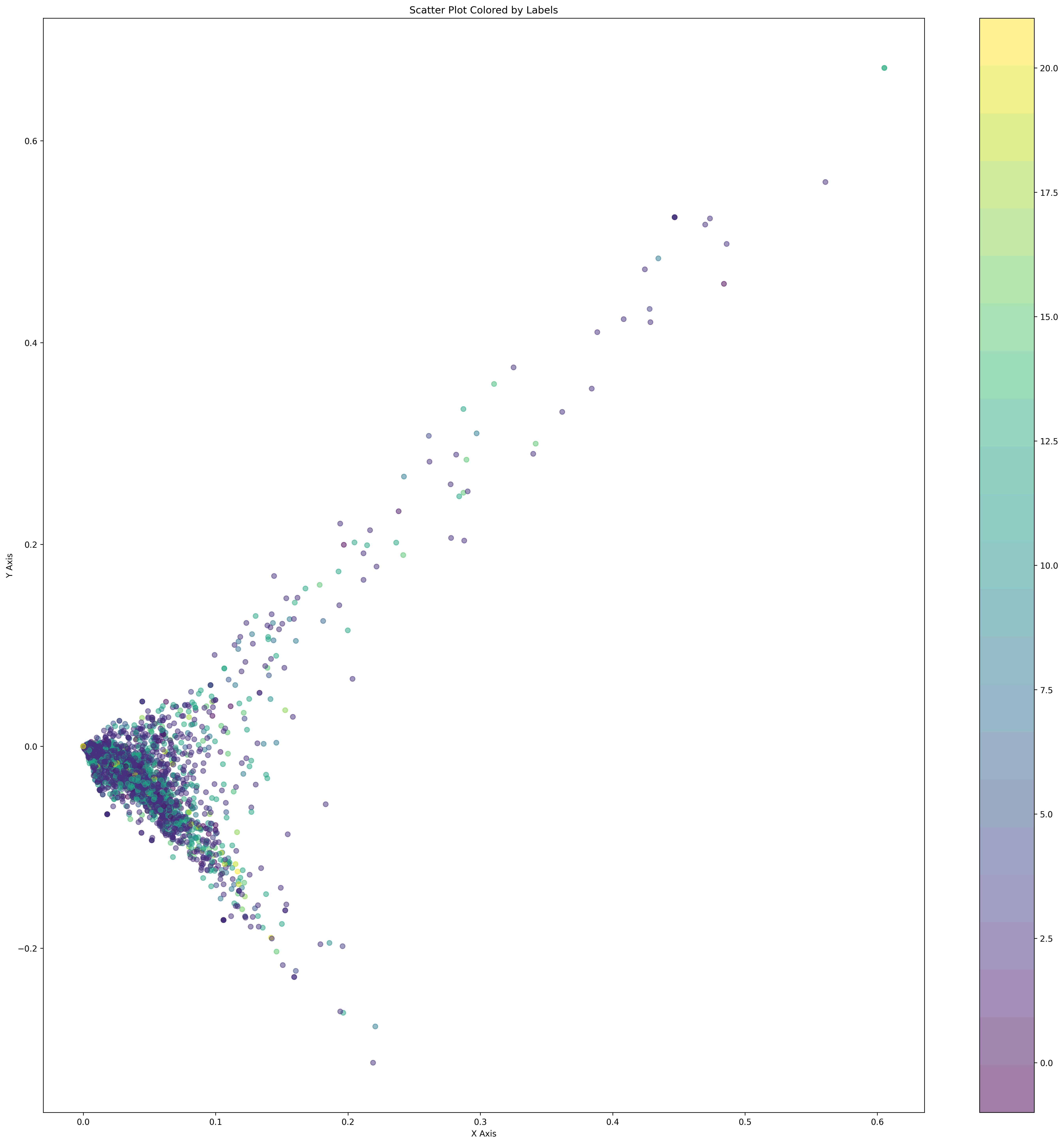
None
23
None
23
None
Visualization by Bokeh#
Now, we can represent each document as a two-dimensional pair (x, y) and visualize it on a scatter plot. Additionally, we have labels for each document, allowing us to color each point (document) on the scatter plot with a different color.
df_point = pd.DataFrame(points_umap, columns = ['x', 'y'])
df_merge = pd.concat([df, df_point], axis='columns')
df_merge
| tag | text | token_text | cleaned | cluster | x | y | |
|---|---|---|---|---|---|---|---|
| 0 | P | 店家很給力,快遞也是相當快,第三次光顧啦 | [店家, 很, 給力, ,, 快遞, 也, 是, 相當快, ,, 第三次, 光顧, 啦] | [店家, 給力, 快遞, 相當快, 第三次, 光顧] | -1 | 7.720855 | 4.369210 |
| 1 | N | 這樣的配置用Vista系統還是有點卡。 指紋收集器。 沒送原裝滑鼠還需要自己買,不太好。 | [這樣, 的, 配置, 用, Vista, 系統, 還是, 有點, 卡, 。, , 指紋,... | [配置, Vista, 系統, 有點, 卡, 指紋, 收集器, 沒送, 原裝, 滑鼠, 需要... | 16 | 9.542090 | 5.581361 |
| 2 | P | 不錯,在同等檔次酒店中應該是值得推薦的! | [不錯, ,, 在, 同等, 檔次, 酒店, 中應, 該, 是, 值得, 推薦, 的, !] | [不錯, 同等, 檔次, 酒店, 中應, 值得, 推薦] | 16 | 8.735751 | 6.942235 |
| 3 | N | 哎! 不會是蒙牛乾的吧 嚴懲真凶! | [哎, !, , 不會, 是, 蒙牛, 乾, 的, 吧, , 嚴懲, 真凶, !] | [蒙牛, 乾, 嚴懲, 真凶] | -1 | 10.393229 | 9.246177 |
| 4 | N | 空尤其是三立電視臺女主播做的序尤其無趣像是硬湊那麼多字 | [空, 尤其, 是, 三立, 電視, 臺, 女主播, 做, 的, 序, 尤其, 無趣, 像是... | [空, 尤其, 三立, 電視, 臺, 女主播, 做, 序, 尤其, 無趣, 像是, 硬, 湊... | -1 | 9.723223 | 4.520297 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 6383 | P | 價效比高、記憶體大、功能全,螢幕超清晰 | [價效, 比高, 、, 記憶體, 大, 、, 功能, 全, ,, 螢幕超, 清晰] | [價效, 比高, 記憶體, 功能, 全, 螢幕超, 清晰] | 2 | 10.678194 | 7.088681 |
| 6384 | N | 你太狠了… 告訴你他們不會喧譁的人,肯定是蒙牛喝多了 | [你, 太狠, 了, …, , 告訴, 你, 他們, 不會, 喧, 譁, 的, 人, ,,... | [太狠, 告訴, 喧, 譁, 人, 肯定, 蒙牛, 喝多] | 2 | 6.966807 | 6.727439 |
| 6385 | N | 醫生居然買了蒙牛,我是喝呢還是不喝呢還是不喝呢? | [ , 醫生, 居然, 買, 了, 蒙牛, ,, 我, 是, 喝, 呢, 還是, 不, 喝,... | [醫生, 買, 蒙牛, 喝, 喝, 喝] | 2 | 8.084755 | 7.613205 |
| 6386 | N | 我只想說 夾蒙牛是不對的 販賣毒品是犯罪行為 | [我, 只, 想, 說, , 夾, 蒙牛, 是, 不, 對, 的, , 販賣, 毒品, ... | [只, 想, 說, 夾, 蒙牛, 販賣, 毒品, 犯罪, 行為] | 12 | 6.046978 | 7.197652 |
| 6387 | P | 蒙牛便宜 | [蒙牛, 便宜] | [蒙牛, 便宜] | 18 | 12.109310 | 11.092052 |
6388 rows × 7 columns
from bokeh.models import ColumnDataSource, Label, LabelSet, Range1d
from bokeh.plotting import figure, output_file, show
from bokeh.io import output_notebook
output_notebook()
def generate_color(x, total):
def color_red_blue(ctr, reverse=False):
r = int(ctr*255)
b = 255-int(ctr*255)
if reverse:
return "#%02x%02x%02x" % (b, 0, r)
else:
return "#%02x%02x%02x" % (r, 0, b)
return color_red_blue(x/total)
print(generate_color(1, 6))
#2a00d5
bokeh.palettes#
p = figure(title = "doc clustering")
colors = df_merge['cluster'].apply(lambda x:generate_color(x, true_k))
from bokeh.palettes import Magma, Inferno, Plasma, Viridis, Cividis, d3
palletes = d3['Category20'][true_k]
colors = [palletes[clu] for clu in df_merge['cluster']]
# print(colors)
p.circle(df_merge["x"], df_merge["y"], color = colors, fill_alpha=0.2, size=10)
show(p)
V2. Visualizing word freq in each cluster#
Store to dict+list for bar chart#
Using defaultdict: https://docs.python.org/3/library/collections.html
from collections import defaultdict, Counter
cdict = defaultdict(Counter)
for k, v in zip(df['cluster'], df['cleaned']):
for word in v:
cdict[k][word] += 1
for c in cdict:
print(cdict[c].most_common(20))
print("-"*80)
[('蒙牛', 67), ('好', 58), ('不錯', 41), ('買', 34), ('說', 29), ('配置', 22), ('系統', 21), ('太', 20), ('感覺', 20), ('喝', 18), ('書', 18), ('速度', 17), ('喜歡', 17), ('價效', 17), ('問題', 16), ('收到', 16), ('房間', 16), ('高', 15), ('酒店', 15), ('功能', 15)]
--------------------------------------------------------------------------------
[('買', 4), ('書', 4), ('系統', 3), ('不錯', 3), ('知道', 3), ('說', 3), ('錢', 3), ('好', 3), ('所有', 3), ('值得', 2), ('時', 2), ('電池', 2), ('故事', 2), ('中', 2), ('蒙牛', 2), ('客服', 2), ('真的', 2), ('內容', 2), ('方面', 2), ('寫', 2)]
--------------------------------------------------------------------------------
[('蒙牛', 15), ('好', 14), ('買', 8), ('不錯', 6), ('喝', 5), ('說', 4), ('房間', 4), ('早餐', 4), ('品牌', 3), ('朋友', 3), ('感覺', 3), ('還在', 2), ('卻', 2), ('生產', 2), ('價格', 2), ('適中', 2), ('沒得', 2), ('想', 2), ('牛奶', 2), ('毛病', 2)]
--------------------------------------------------------------------------------
[('蒙牛', 72), ('不錯', 43), ('好', 36), ('喝', 15), ('厚', 15), ('牛', 14), ('外觀', 12), ('抵制', 12), ('喜歡', 11), ('逼', 10), ('東西', 10), ('漂亮', 9), ('挺', 9), ('功能', 8), ('還不錯', 8), ('包裝', 7), ('說', 7), ('買', 6), ('質量', 6), ('好看', 6)]
--------------------------------------------------------------------------------
[('蒙牛', 40), ('好', 24), ('買', 20), ('不錯', 18), ('感覺', 17), ('太', 17), ('酒店', 13), ('喜歡', 12), ('燙', 11), ('說', 11), ('喝', 10), ('一個', 10), ('效果', 9), ('書', 9), ('系統', 8), ('東西', 8), ('價格', 8), ('人', 8), ('價效', 8), ('比較', 8)]
--------------------------------------------------------------------------------
[('蒙牛', 15), ('好', 13), ('買', 11), ('不錯', 10), ('後', 8), ('說', 8), ('書', 6), ('太', 6), ('感覺', 5), ('只能', 5), ('方便', 5), ('知道', 4), ('一個', 4), ('功能', 3), ('外觀', 3), ('設計', 3), ('不換', 3), ('不好', 3), ('東西', 3), ('價格', 3)]
--------------------------------------------------------------------------------
[('蒙牛', 8), ('說', 7), ('一個', 5), ('買', 5), ('好', 4), ('不錯', 3), ('喜歡', 3), ('客服', 3), ('太', 2), ('看到', 2), ('鈴聲', 2), ('挺', 2), ('不好', 2), ('已經', 2), ('次奧', 2), ('標王', 2), ('電池', 2), ('這家', 1), ('如家', 1), ('地段', 1)]
--------------------------------------------------------------------------------
[('蒙牛', 12), ('好', 10), ('不錯', 9), ('感覺', 7), ('喜歡', 7), ('寫', 5), ('有點', 5), ('買', 5), ('說', 4), ('鍵盤', 4), ('內容', 4), ('三星', 4), ('確實', 3), ('這本書', 3), ('螢幕', 3), ('屏', 3), ('外觀', 3), ('值得', 3), ('功能', 3), ('做工', 3)]
--------------------------------------------------------------------------------
[('蒙牛', 149), ('好', 127), ('不錯', 89), ('買', 66), ('說', 53), ('書', 41), ('房間', 36), ('酒店', 34), ('後', 33), ('價格', 31), ('喝', 27), ('外觀', 27), ('系統', 27), ('感覺', 27), ('價效', 26), ('人', 26), ('有點', 26), ('喜歡', 25), ('方便', 25), ('支援', 24)]
--------------------------------------------------------------------------------
[('蒙牛', 64), ('好', 62), ('不錯', 37), ('買', 27), ('酒店', 23), ('說', 23), ('系統', 19), ('喝', 18), ('書', 15), ('人', 13), ('速度', 13), ('外觀', 12), ('價格', 12), ('適合', 12), ('房間', 12), ('差', 12), ('配置', 12), ('功能', 11), ('感覺', 11), ('服務', 11)]
--------------------------------------------------------------------------------
[('蒙牛', 11), ('好', 9), ('酒店', 8), ('書', 8), ('房間', 7), ('不錯', 7), ('感覺', 5), ('購買', 4), ('服務', 4), ('喝', 3), ('買', 3), ('XP', 3), ('好像', 3), ('沒什麼', 3), ('螢幕', 3), ('介面', 3), ('物有所值', 2), ('整潔', 2), ('環境', 2), ('已經', 2)]
--------------------------------------------------------------------------------
[('蒙牛', 14), ('好', 11), ('買', 8), ('不錯', 6), ('便宜', 6), ('比較', 5), ('房間', 4), ('價格', 4), ('不好', 4), ('服務', 4), ('書', 4), ('挺', 3), ('好看', 3), ('小', 3), ('今天', 3), ('寫', 3), ('還行', 3), ('配置', 3), ('問題', 3), ('人', 3)]
--------------------------------------------------------------------------------
[('蒙牛', 27), ('好', 21), ('說', 13), ('書', 12), ('不好', 11), ('不錯', 10), ('感覺', 10), ('人', 10), ('買', 9), ('太', 7), ('速度', 7), ('一個', 7), ('價效', 7), ('價格', 6), ('酒店', 6), ('喜歡', 6), ('話', 6), ('外觀', 6), ('臺', 6), ('方便', 5)]
--------------------------------------------------------------------------------
[('好', 15), ('蒙牛', 12), ('不錯', 10), ('驅動', 8), ('房間', 6), ('螢幕', 6), ('外觀', 6), ('買', 5), ('系統', 5), ('人', 5), ('喜歡', 5), ('XP', 5), ('速度', 5), ('安裝', 5), ('已', 5), ('功能', 4), ('問題', 4), ('很大', 4), ('月', 4), ('挺', 4)]
--------------------------------------------------------------------------------
[('蒙牛', 6), ('書', 3), ('元', 3), ('買', 3), ('筆記', 2), ('滑鼠', 2), ('本本', 2), ('散', 2), ('後', 2), ('問題', 2), ('一個', 2), ('水器', 2), ('http', 2), ('t', 2), ('cn', 2), ('陳', 2), ('喝', 2), ('還不錯', 2), ('螢幕', 2), ('效果', 2)]
--------------------------------------------------------------------------------
[('蒙牛', 19), ('好', 12), ('不錯', 7), ('喝', 5), ('系統', 5), ('買', 5), ('書', 4), ('電池', 4), ('價效', 4), ('部落', 3), ('格', 3), ('真是', 3), ('不好', 3), ('最', 3), ('功能', 3), ('酒店', 3), ('價格', 3), ('抵制', 3), ('地方', 3), ('垃圾', 3)]
--------------------------------------------------------------------------------
[('蒙牛', 10), ('說', 7), ('好', 7), ('買', 6), ('房間', 5), ('酒店', 4), ('功能', 4), ('漂亮', 3), ('鍵盤', 3), ('比較', 3), ('小', 3), ('時間', 3), ('不錯', 3), ('逼', 3), ('螢幕', 3), ('有點', 2), ('伊利', 2), ('看到', 2), ('網友', 2), ('價格', 2)]
--------------------------------------------------------------------------------
[('蒙牛', 242), ('好', 220), ('不錯', 167), ('買', 102), ('房間', 82), ('說', 70), ('感覺', 65), ('酒店', 63), ('方便', 55), ('外觀', 51), ('系統', 51), ('服務', 50), ('太', 48), ('螢幕', 46), ('書', 46), ('喝', 46), ('價格', 45), ('後', 43), ('速度', 43), ('價效', 42)]
--------------------------------------------------------------------------------
[('蒙牛', 738), ('好', 516), ('不錯', 419), ('買', 256), ('酒店', 195), ('說', 176), ('房間', 164), ('感覺', 155), ('喝', 152), ('外觀', 144), ('價效', 132), ('有點', 128), ('價格', 126), ('方便', 124), ('螢幕', 124), ('後', 123), ('系統', 121), ('比較', 118), ('喜歡', 111), ('小', 109)]
--------------------------------------------------------------------------------
[('蒙牛', 15), ('不錯', 12), ('好', 12), ('房間', 9), ('太', 6), ('買', 6), ('後', 6), ('酒店', 5), ('人', 5), ('這本書', 5), ('螢幕', 5), ('時間', 5), ('驅動', 4), ('感覺', 4), ('說', 4), ('鍵盤', 4), ('新', 3), ('挺', 3), ('太小', 3), ('一些', 3)]
--------------------------------------------------------------------------------
[('蒙牛', 18), ('好', 13), ('買', 8), ('書', 6), ('不錯', 6), ('功能', 5), ('一個', 5), ('感覺', 4), ('螢幕', 4), ('喝', 4), ('月', 4), ('噁', 4), ('故事', 3), ('時間', 3), ('聽', 3), ('說', 3), ('不喜歡', 3), ('方便', 3), ('營養', 2), ('卻', 2)]
--------------------------------------------------------------------------------
import pandas as pd
df1 = pd.DataFrame(list(cdict[0].most_common(5)), columns = ['word', 'n'])
df1
V3. (Deprecated) Heatmap by seaborn#
"""
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Convert the document-term matrix to a dense format if it's sparse
X_dense = X.toarray()
# Create a DataFrame from the dense matrix for easier manipulation
df = pd.DataFrame(X_dense)
# Add cluster labels to the DataFrame
df['cluster'] = cluster.labels_
# Sort the DataFrame by cluster labels
df = df.sort_values('cluster')
# Drop the cluster column for the heatmap
df = df.drop(columns=['cluster'])
# Plotting the heatmap
plt.figure(figsize=(12, 8))
sns.heatmap(df, cmap='viridis')
plt.xlabel('Terms')
plt.ylabel('Documents')
plt.title('Heatmap of Term Frequencies per Document')
plt.show()
"""
Barh by seaborn#
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['Heiti TC']
for clu in range(true_k):
df1 = pd.DataFrame(list(cdict[clu].most_common(20)), columns = ['word', 'n'])
plt.figure(figsize=(6, 3), dpi=120)
df_data = df1.sort_values('n', ascending=False)
# print(df_data)
sns.barplot(x='n',
y='word',
data=df_data,
label='word',
color='royalblue',
)