Chapter 6 From base R to dplyr
From base to tidyverse style
相較於R base的較為傳統的R編程風格,tidyverse style的R programming具有以下幾個特點:
基於tidy data理念:tidyverse style的R programming基於tidy data理念,即資料應該以規律的方式組織,以方便分析和視覺化。tidyverse style的R程式庫提供了一些工具和函數,用於處理和轉換tidy data格式的資料,如dplyr、tidyr等。
使用管道操作符:tidyverse style的R programming通常使用管道操作符(%>%),將資料通過多個函數連接起來,形成一個清晰和易於理解的資料處理流程。使用管道操作符可以簡化程式碼並提高程式的可讀性。
強調函數庫的一致性:tidyverse style的R programming強調函數庫之間的一致性,即不同函數庫之間使用相似的函數名稱、參數名稱和返回值等,以方便使用者的學習和使用。
使用簡潔的命名方式:tidyverse style的R programming通常使用簡潔和易於理解的變數和函數命名方式,例如使用動詞表示操作,使用名詞表示資料,以方便使用者理解程式碼的含義。
提供高級的視覺化工具:tidyverse style的R programming提供了一些高級的視覺化工具,如ggplot2、gganimate等,可以幫助使用者更加輕鬆地進行資料視覺化和探索。
6.1 dplyr
dplyr是一個tidyverse風格的R程式庫,用於對資料進行快速、一致、直觀的操作和轉換。dplyr提供了一些高效能的函數和工具,如filter、select、mutate、group_by和summarize等,用於對資料進行選擇、篩選、轉換、分組和摘要等操作。
以下是dplyr常用的函數:
filter:用於選擇符合特定條件的資料列。select:用於選擇特定的欄位。mutate:用於新增或修改欄位。group_by:用於按照特定欄位進行分組。summarize:用於對分組後的資料進行摘要統計。arrange:用於按照欄位的特定順序進行排序。
dplyr具有以下優點:
簡潔而直觀的語法:dplyr的函數名稱和語法都十分簡潔而直觀,易於使用和理解,尤其對於新手來說更加友好。
高效的運行速度:dplyr的設計考慮了資料處理的效率,使用C++實現了部分函數,因此dplyr在處理大型資料集時運行速度較快。
與tidyverse相容:dplyr與其他tidyverse程式庫,如ggplot2和tidyr,可以很好地相容,並且能夠與其他常用的R程式庫進行集成,提供更加全面和高效的資料分析和可視化工具。
6.2 Taipie Theft Count (base to dplyr)
6.2.1 Reading data
# Read by read_csv()
# Will raise error
# Error in make.names(x) : invalid multibyte string at '<bd>s<b8><b9>'
# df <- read_csv("data/tp_theft.csv")
# read_csv() with locale = locale(encoding = "Big5")
library(readr)
# df <- read.csv("data/臺北市住宅竊盜點位資訊-UTF8-BOM.csv", fileEncoding = "Big5")
df <- read_csv("data/臺北市住宅竊盜點位資訊-UTF8-BOM.csv", locale = locale(encoding = "Big5"))
head(df) ## # A tibble: 6 × 5
## 編號 案類 發生日期 發生時段 發生地點
## <dbl> <chr> <dbl> <chr> <chr>
## 1 1 住宅竊盜 1030623 08~10 臺北市中正區廈門街91~120號
## 2 2 住宅竊盜 1040101 00~02 臺北市文山區萬美里萬寧街1~30號
## 3 3 住宅竊盜 1040101 00~02 臺北市信義區富台里忠孝東路5段295巷6弄1~30號
## 4 4 住宅竊盜 1040101 06~08 臺北市中山區新生北路1段91~120號
## 5 5 住宅竊盜 1040101 10~12 臺北市文山區明興里興隆路4段1~30號
## 6 6 住宅竊盜 1040102 00~02 臺北市士林區天福里1鄰忠誠路2段130巷1~30號6.2.2 Cleaning data I
- Renaming variables by
select() - Generating variable year by
mutate() - Generating variable month by
mutate() - Retrieving area by
mutate()
6.2.2.2 (2) Without pipeline II
library(stringr)
df_selected <- select(df, id = 編號, cat = 案類, date = `發生日期`, timestamp = `發生時段`, location = `發生地點`)
df_selected <- mutate(df_selected, year = date %/% 10000)
df_selected <- mutate(df_selected, month = date %/% 100 %% 100)
df_selected <- mutate(df_selected, area = str_sub(location, 4, 6))
df_selected <- mutate(df_selected, county = str_sub(location, 1, 3))6.2.3 Cleaning data II
- Filtering out irrelevant data records
# readr::guess_encoding("data/tp_theft.csv")
df_filtered <- df_selected %>%
filter(county == "臺北市") %>%
filter(year >= 104) %>%
filter(!county %in% c("中和市", "板橋市")) %>%
filter(!timestamp %in% c("01~03","03~05", "05~07", "09~11", "11~13", "11~03", "12~15", "15~17", "15~18", "17~19", "18~21", "19~21", "21~23", "21~24", "23~01"))6.2.4 Long to wide table
count()two variablespivot_wider()spread one variable as columns to wide form
6.2.5 Plot with long table
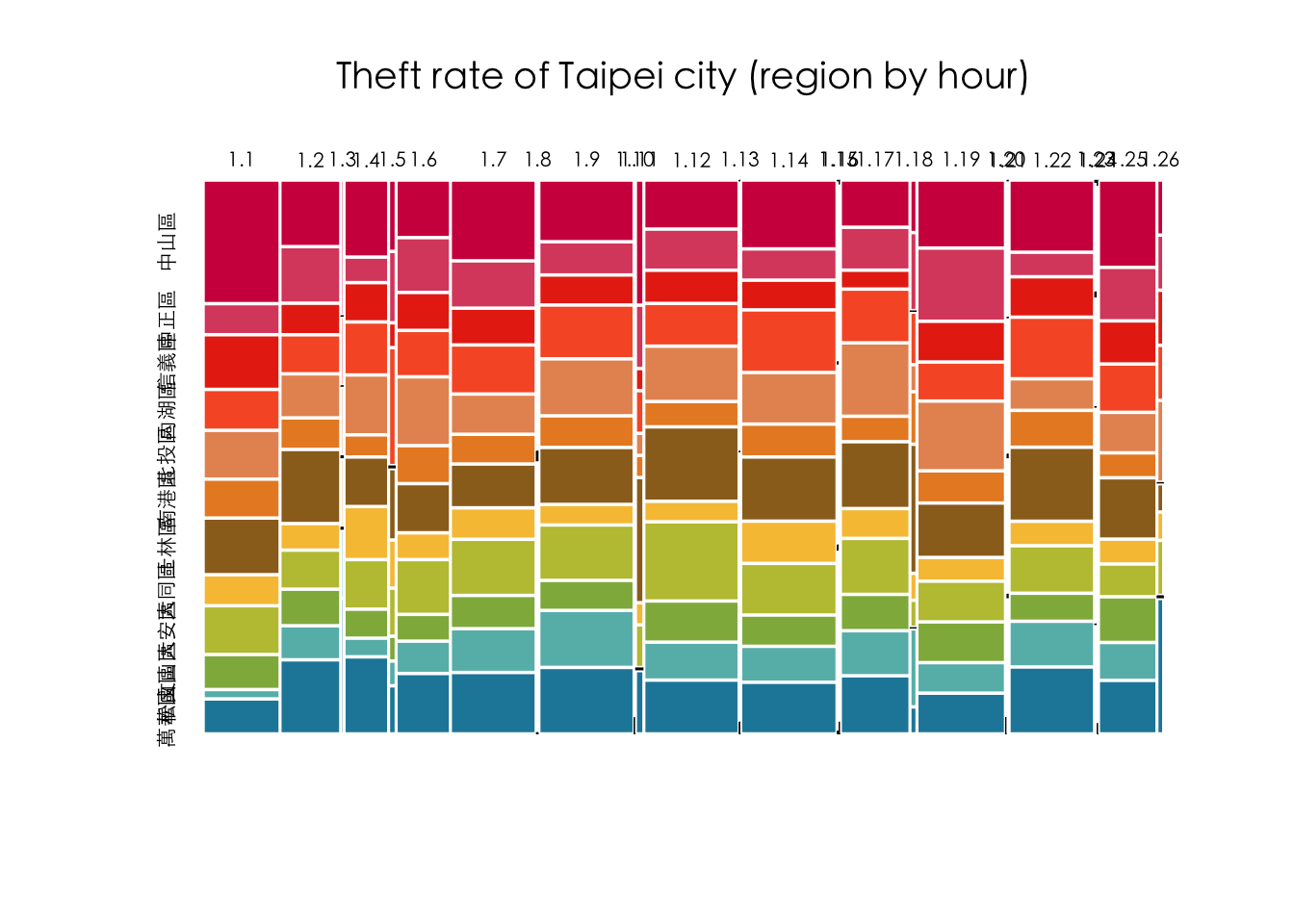
df_filtered %>%
count(timestamp, area) %>%
ggplot() +
aes(x = timestamp, y = n, fill = area) +
geom_col(position = "dodge") +
facet_wrap(. ~ area) +
# facet_wrap(. ~ area, nrow=length(unique(df_filtered$area))) +
# facet_grid(. ~ area) +
theme_minimal() +
theme(
text = element_text(family = "Heiti TC Light"), # Apply font to all text
axis.title = element_text(family = "Heiti TC Light"), # X and Y axis labels
axis.text = element_text(family = "Heiti TC Light"), # X and Y axis values
legend.text = element_text(family = "Heiti TC Light"), # Legend text
legend.title = element_text(family = "Heiti TC Light"), # Legend title
axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5)
)
6.2.6 Clean version
library(readr)
library(tidyverse)
df <- read_csv("data/臺北市住宅竊盜點位資訊-UTF8-BOM.csv", locale = locale(encoding = "Big5"))
df_selected <- df %>%
select(id = 編號,
cat = 案類,
date = `發生日期`,
timestamp = `發生時段`,
location = `發生地點`) %>%
mutate(year = date %/% 10000) %>%
mutate(month = date %/% 100 %% 100) %>%
mutate(area = stringr::str_sub(location, 4, 6)) %>%
mutate(county = stringr::str_sub(location, 1, 3))
df_filtered <- df_selected %>%
filter(county == "臺北市") %>%
filter(year >= 104) %>%
filter(!area %in% c("中和市", "板橋市")) %>%
filter(!timestamp %in% c("01~03","03~05", "05~07", "09~11", "11~13", "11~03", "12~15", "15~17", "15~18", "17~19", "18~21", "19~21", "21~23", "21~24", "23~01"))
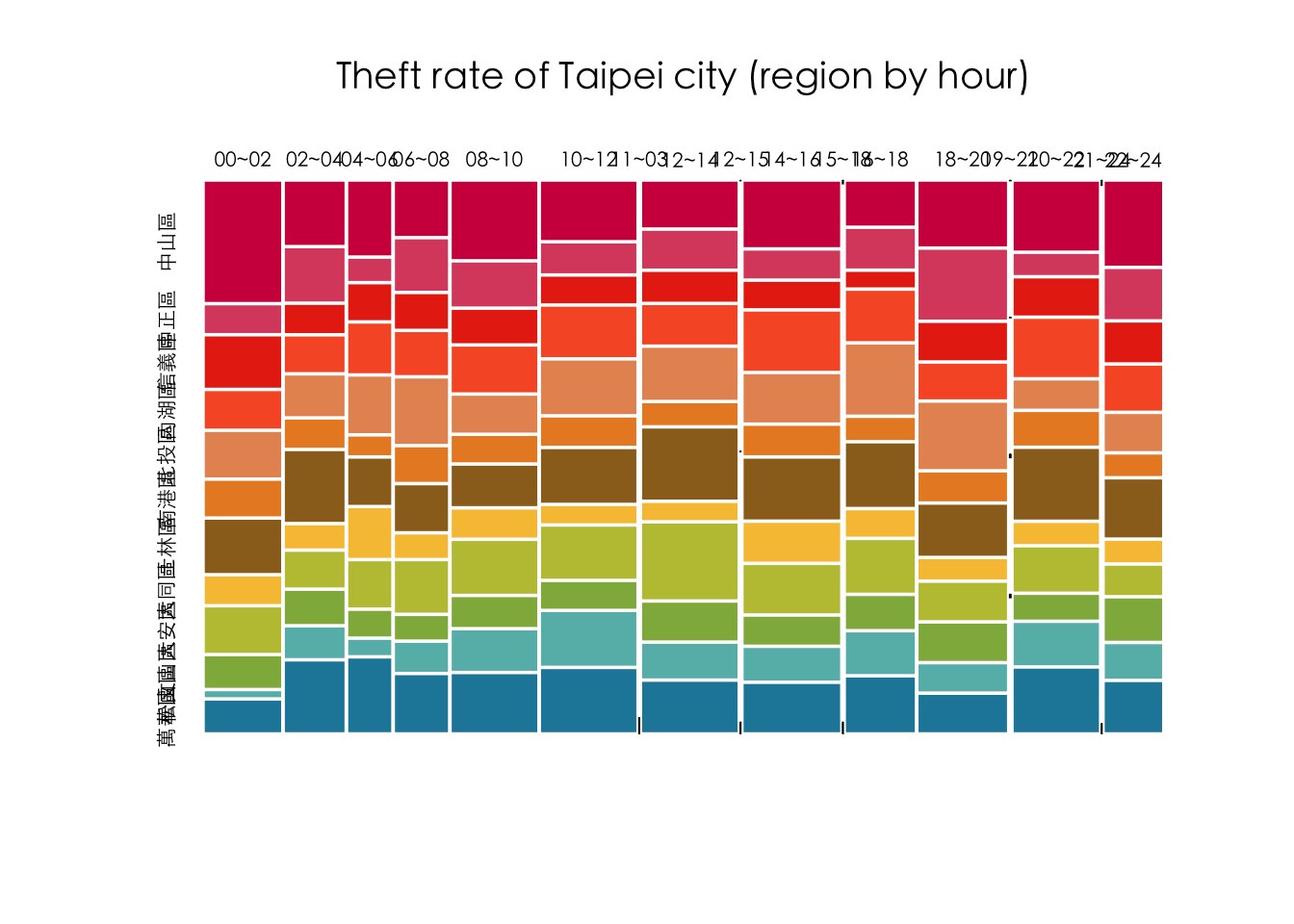
df_filtered %>%
count(timestamp, area) %>%
ggplot() +
aes(x = timestamp, y = n, fill = area) +
geom_col(position = "dodge") +
facet_wrap(. ~ area) +
# facet_wrap(. ~ area, nrow=length(unique(df_filtered$area))) +
# facet_grid(. ~ area) +
theme_minimal() +
theme(
text = element_text(family = "Heiti TC Light"), # Apply font to all text
axis.title = element_text(family = "Heiti TC Light"), # X and Y axis labels
axis.text = element_text(family = "Heiti TC Light"), # X and Y axis values
legend.text = element_text(family = "Heiti TC Light"), # Legend text
legend.title = element_text(family = "Heiti TC Light"), # Legend title
axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5)
)
6.3 Paid Maternity Leave
這個案例「The world is getting better at paid maternity leave. The U.S. is not」為華盛頓郵報記者Melissa Etehad和Jeremy C.F. Lin在2016年8月13日所撰寫的新聞。記者選定了「美國沒有產假支薪」作為新聞切入點。在呈現的時候,就必須要盡可能地凸顯這樣的情形。一般來說,會繪製世界地圖且用顏色來凸顯美國是目前少數沒有產假支薪的國家之一如下:

6.3.1 The Data
該筆資料來自位於UCLA公衛學院的World Policy Analysis Center,其包含兩個壓縮檔,分別為橫斷式資料與部分資料的縱貫性資料。就產假支薪而言,其調查了198個國家的政策,將支薪週數分為五個等級,並蒐錄了1995年至2013年間的變化(matleave_95~matleave13)。通常在資料分析時,應先閱讀資料了解資料。首先要先觀察資料,開啟資料後概略如下:
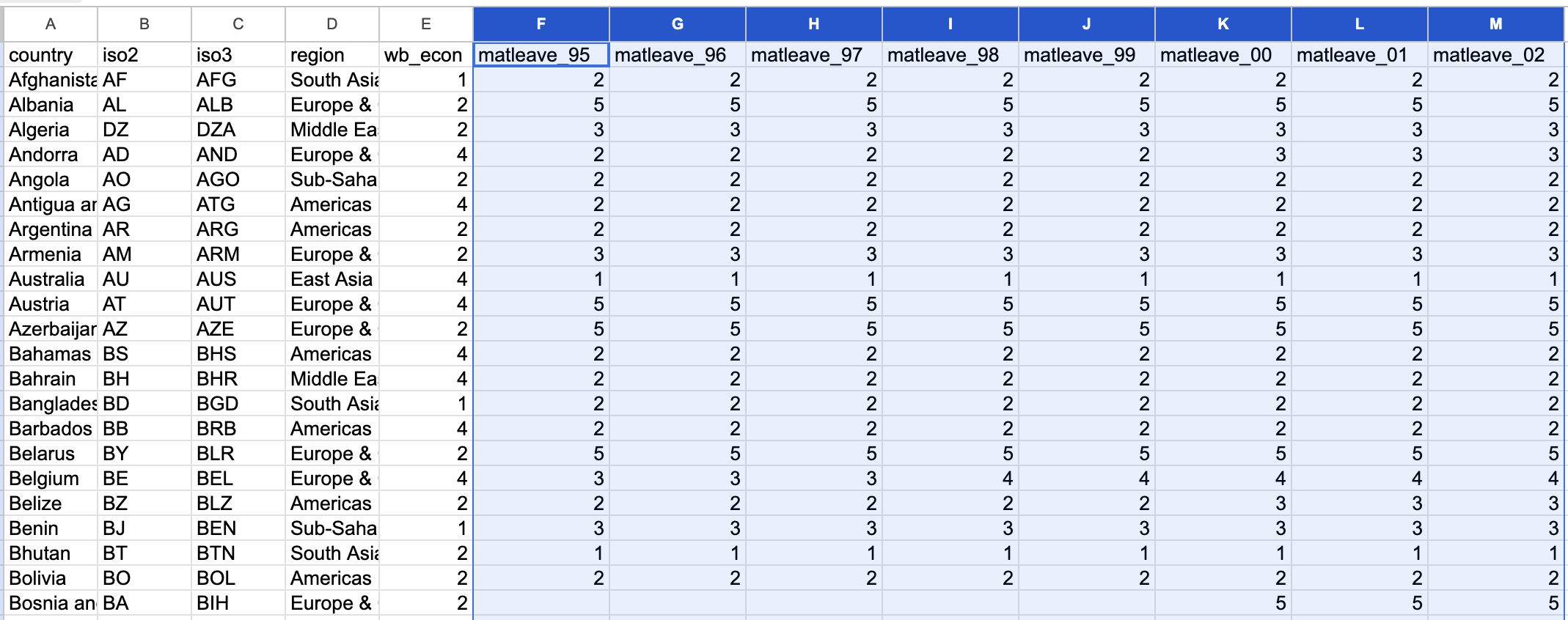
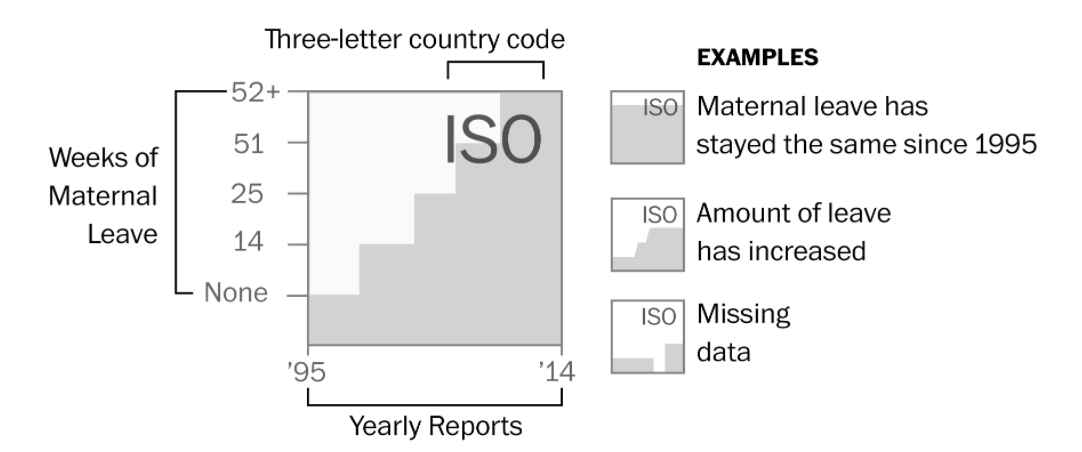
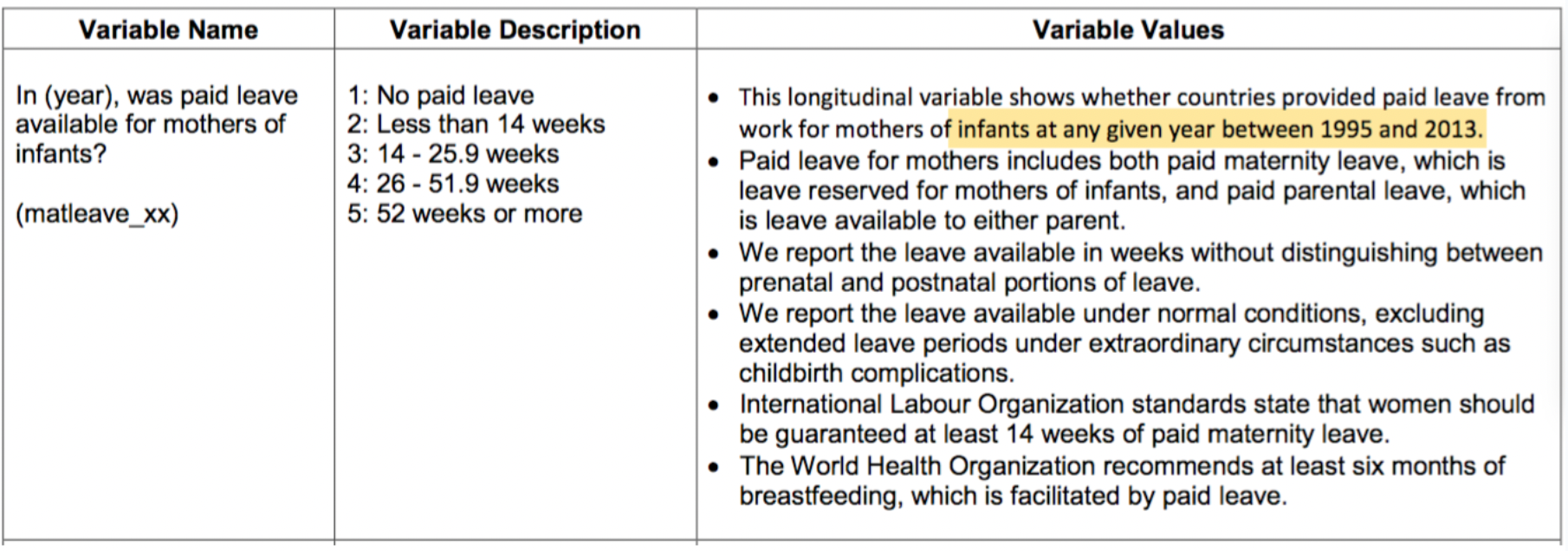
打開資料後便先觀察資料的「列(Row)」是什麼?又有哪些「欄(Column)」?通常在列上的會是逐筆的觀察值,如前述資料每一筆是個國家,而欄上面則是每個觀察所觀察到的變項,例如國名縮寫(iso2、iso3)、地區(region)、經濟等級(wb_econ)、和本案例所要觀察的產假支付等級。但產假支付等級可以看從matleave_95到matleave_13共19欄是19年的資料,數值為1到5,空白的通常是該年沒記錄到的缺漏值。通常統計資料如果是用等第來紀錄的話,會給編碼表,也就是1到5分別代表哪種等級、哪種程度。這份資料也有給編碼表如下,產假給付程度在該調查中分為五個等級,包含1(0週)、2(0-14週)、3(14-25週)、4(26-51週)、5(52週以上)等。
6.3.2 Advanced Visual Strategies
但如果只是繪製地圖,卻又略顯單薄。而該筆來自Word Policy Analysis Center資料其實含有自1995年至2003年共19年的資料(本案例即就是下載該中心所分享的調查資料,不用申請帳號)。於是該專題的作者便利用這些歷史資料,進一步凸顯美國在這方面一直沒有改變,始終都是保持0週,即使其他各國逐漸在調高產假的給付程度。但要處理197個國家的在19年間的變化相當不易。若為每年繪製一張世界地圖,然後以動畫或動態卷軸來凸顯這19年間美國的變化,也會因為國家數過多而難以聚焦在作者想突顯的美國。
而這便是作者在視覺化上相當具有巧思的地方。作者便從給付程度最高的層級開始做長條圖,共五個階層的子圖。而每個階層的子圖,作者又將該層級的圖分為「保持不變(Stay Same)」和「持續增加(Increase)」兩組。經過這樣的分組,會得到9個子圖。分別為等級5(保持不變、持續增加)、等級4(保持不變、持續增加)、…、等級1(保持不變)。讀者在看的時候,會依次看到給付程度最高到最低的國家,也可以看到哪些國家在這19年間制度有所變化(通常是增加)。但看到最後的時候,便會看到美國的情形,即是無產假給付。
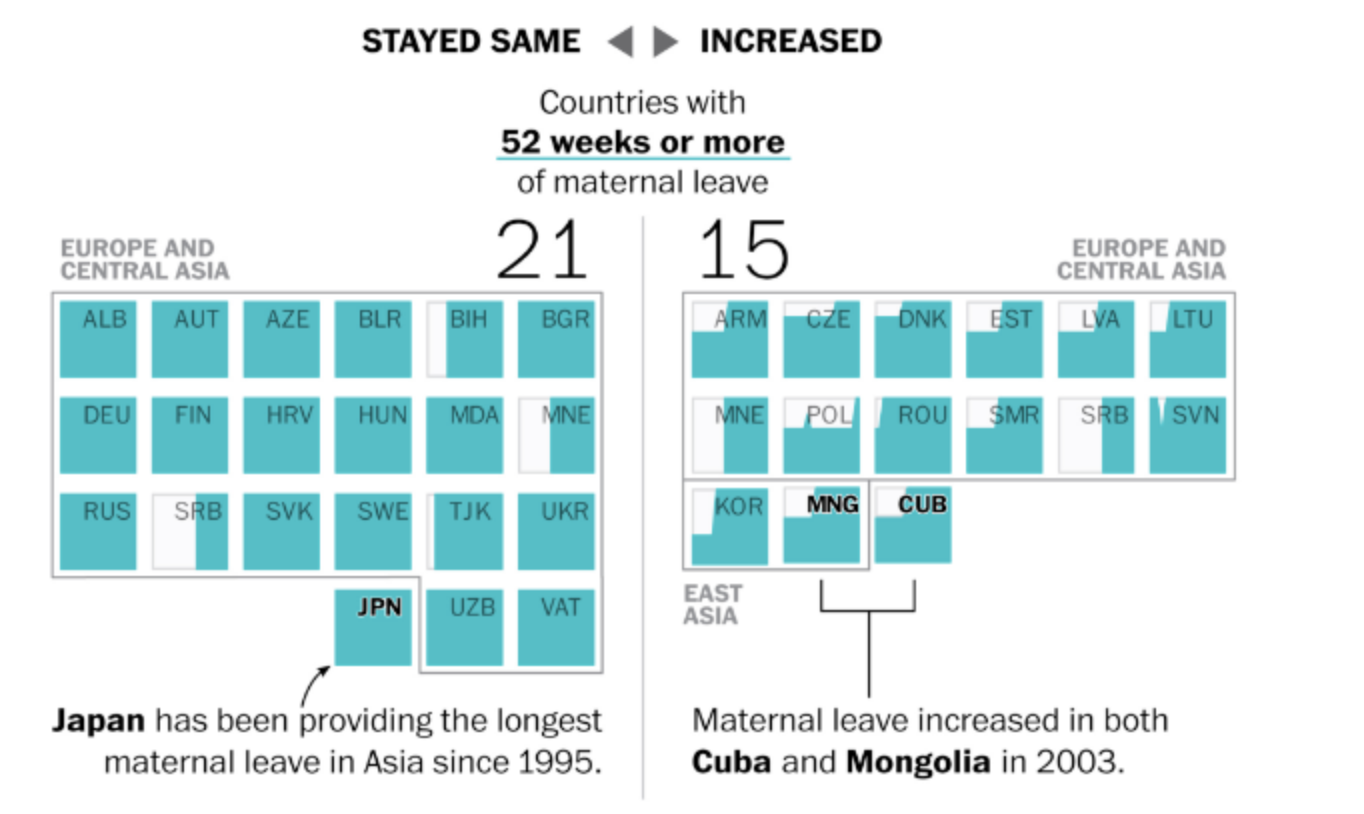
6.3.3 Code by base R
library(readxl)
# readxl::read_excel() to import the xls file
df <- read_excel("data/WORLD-MACHE_Gender_6.8.15.xls", "Sheet1", col_names=T)
# select iso3, and matleave columns by index
matleave <- df[ , c(3, 6:24)]
# str() to inspect the data structure of
str(matleave)## tibble [197 × 20] (S3: tbl_df/tbl/data.frame)
## $ iso3 : chr [1:197] "AFG" "ALB" "DZA" "AND" ...
## $ matleave_95: num [1:197] 2 5 3 2 2 2 2 3 1 5 ...
## $ matleave_96: num [1:197] 2 5 3 2 2 2 2 3 1 5 ...
## $ matleave_97: num [1:197] 2 5 3 2 2 2 2 3 1 5 ...
## $ matleave_98: num [1:197] 2 5 3 2 2 2 2 3 1 5 ...
## $ matleave_99: num [1:197] 2 5 3 2 2 2 2 3 1 5 ...
## $ matleave_00: num [1:197] 2 5 3 3 2 2 2 3 1 5 ...
## $ matleave_01: num [1:197] 2 5 3 3 2 2 2 3 1 5 ...
## $ matleave_02: num [1:197] 2 5 3 3 2 2 2 3 1 5 ...
## $ matleave_03: num [1:197] 2 5 3 3 2 2 2 3 1 5 ...
## $ matleave_04: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_05: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_06: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_07: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_08: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_09: num [1:197] 2 5 3 3 2 2 2 5 1 5 ...
## $ matleave_10: num [1:197] 2 5 3 3 2 2 2 5 NA 5 ...
## $ matleave_11: num [1:197] 2 5 3 3 2 2 2 5 3 5 ...
## $ matleave_12: num [1:197] 2 5 3 3 2 2 2 5 3 5 ...
## $ matleave_13: num [1:197] 2 5 3 3 2 2 2 5 3 5 ...# select all NA cells and assign 0 to them
matleave[is.na(matleave)] <- 0
# filter rows by condition
m5 <- matleave[matleave$'matleave_13' == 5, ]
# filter rows by condition
m55<- m5[m5$'matleave_95' == 5,]
# plot
par(mfrow=c(4,6), mai= c(0.2, 0.2, 0.2, 0.2))
for (i in c(1:nrow(m55))){
barplot(unlist(m55[i,-1]),
border=NA, space=0,xaxt="n", yaxt="n", ylim = c(0,5))
title(m55[i,1], line = -4, cex.main=3)
}
6.3.4 Code by dplyr
首先,程式碼使用 filter() 函數篩選出符合條件的列,其中 matleave_13 和 matleave_95 兩欄都必須等於 5。接著,pivot_longer() 函數將資料框轉換成長格式(long format),將從第二欄到第二十欄的資料整合到兩個欄位 year 和 degree 中。這裡 names_to 參數指定新欄位 year 的名稱,values_to 參數指定新欄位 degree 的名稱,cols 參數指定要整合的欄位範圍。
接下來,replace_na() 函數將 degree 欄位中的 NA 值替換為 0。然後,mutate() 函數使用 as.POSIXct() 函數將 year 欄位中的字串轉換為日期時間格式,再使用 year() 函數從日期時間中提取年份,最終將年份資訊存儲回 year 欄位中。其中 “matleave_%y” 是日期時間格式字串,其中 “%y” 表示兩位數的年份(例如 “13”)。這樣就將 “matleave_13”、“matleave_14” 等字串轉換成了對應的日期時間。
ggplot() 函數創建了一個空的 ggplot2 圖形物件,使用 aes() 函數定義了 x 軸 year 和 y 軸 degree 的變數名稱。geom_col() 函數指定用長條圖呈現資料,設置了顏色和填充顏色。ylim() 函數限制了 y 軸的範圍,將其設置為 0 到 5,無論y軸資料有沒有到5或者是否超過5,都會限定在0到5之間。facet_wrap() 函數則根據 iso3 欄位生成多個子圖。最後,theme_void() 函數將圖形主題設置為空白,不帶任何邊框或背景。
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.1 ✔ tibble 3.2.1
## ✔ lubridate 1.9.4 ✔ tidyr 1.3.1
## ✔ purrr 1.0.4
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsoptions(scipen = 999)
library(readxl)
matleave <- read_excel("data/WORLD-MACHE_Gender_6.8.15.xls", "Sheet1", col_names=T) %>%
select(iso3, 6:24)
matleave %>%
filter(matleave_13 == 5, matleave_95 == 5) %>%
pivot_longer(names_to = "year", values_to = "degree", cols = 2:20) %>%
replace_na(list(degree = 0)) %>%
mutate(year = year(as.POSIXct(strptime(year, "matleave_%y")))) %>%
ggplot() +
aes(year, degree) +
geom_col(color = "royalblue", fill = "royalblue") +
ylim(0, 5) +
facet_wrap(~ iso3) +
theme_void()
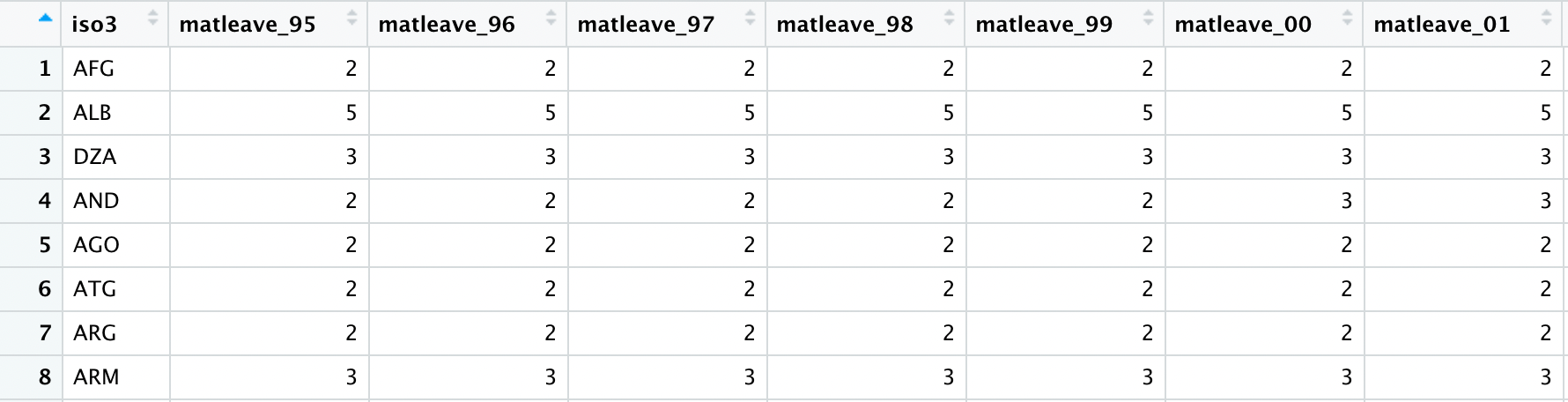
下圖為原始資料的截圖,matleave_95代表1995年的資料,每個變數的數據1至5分別代表產假時給付薪水的月數區間共有五個區間。區間大小通常需要查看編碼簿來獲取定義。
這類資料由於採用數字(其實是Factor)來替代類別,通常隨著數據會釋出該調查的編碼簿(Code Book),這個案例的編碼(1至5)如下:
6.3.5 Generating each
在 R 中,函式是一個可重複使用的程式碼塊,可以接受輸入參數,並返回計算結果。函式可以簡化程式碼,使其更易於維護和修改。為了不要重複相同的程式碼,以下程式碼將視覺化的部分改用「函式」來進行撰寫,再輸入不同子圖所要使用的資料來進行繪圖。
在這個程式碼中,generating_plot() 是一個自定義的函式,它接受一個資料框 df 作為輸入參數。成對大括號內部為該函式所執行的步驟,包含pivot_longer()、replace_na()等。輸出則是一個 ggplot2 圖形物件,其中包含了將這些資料轉換為長條圖的視覺化表示。
在 R 中,創建一個函式需要使用 function() 關鍵字。一個最簡單的函式可能只包含一個輸入參數和一個返回值,例如:my_function <- function(x) {return(x^2)}。在這個例子中,函式名稱是 my_function,它有一個輸入參數 x,函式主體是 x^2,表示將輸入的 x 參數平方。函式主體的執行結果通過 return() 函數返回,並可以存儲到變數中,例如:result <- my_function(3)。函式的定義亦可包含多個輸入參數,可以用數字、list、或Data.Frame等當成輸入參數。
library(tidyverse)
options(scipen = 999)
library(readxl)
matleave <- read_excel("data/WORLD-MACHE_Gender_6.8.15.xls", "Sheet1", col_names=T) %>%
select(iso3, 6:24)
generating_plot <- function(df){
df %>%
pivot_longer(names_to = "year", values_to = "degree", cols = 2:20) %>%
replace_na(list(degree = 0)) %>%
mutate(year = year(as.POSIXct(strptime(year, "matleave_%y")))) %>%
ggplot() +
aes(year, degree) +
geom_col(color = "royalblue", fill = "royalblue") +
ylim(0, 5) +
facet_wrap(~ iso3) +
theme_void() +
theme(strip.text = element_text(size = 14, face = "bold", vjust=0.5),
strip.placement = "inside"
)
}
matleave %>% filter(matleave_13 == 5, matleave_95 == 5) %>% generating_plot()
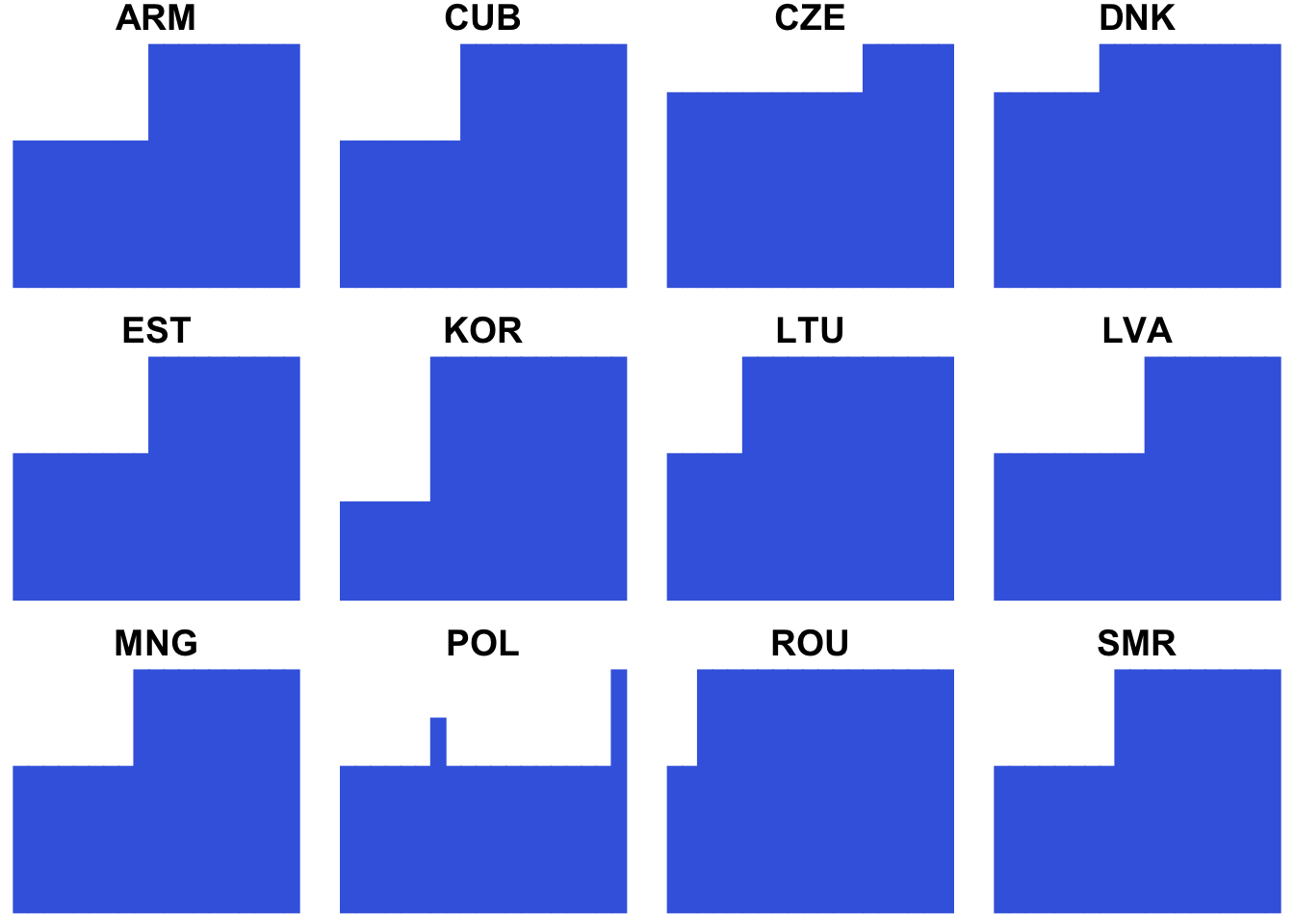




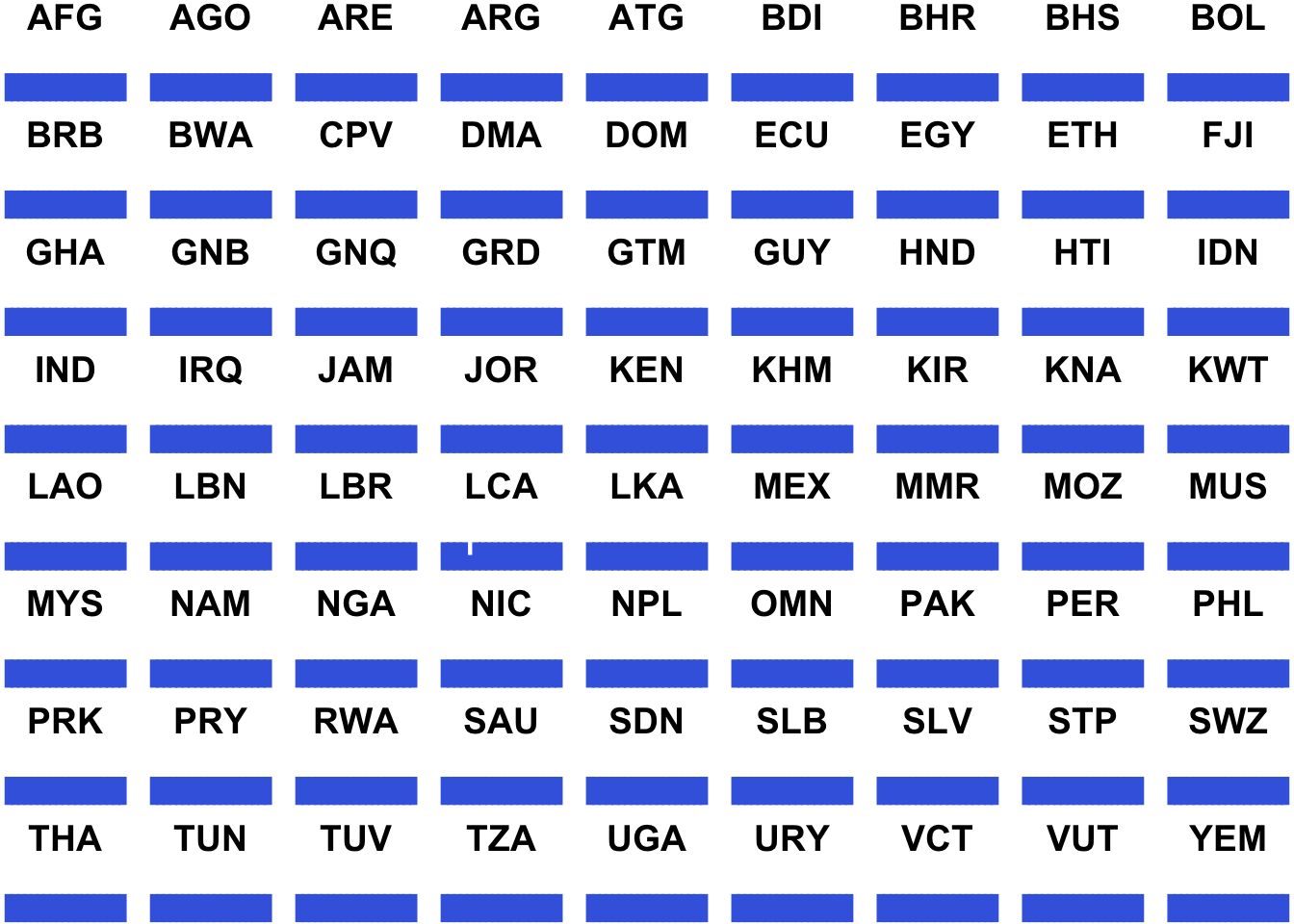
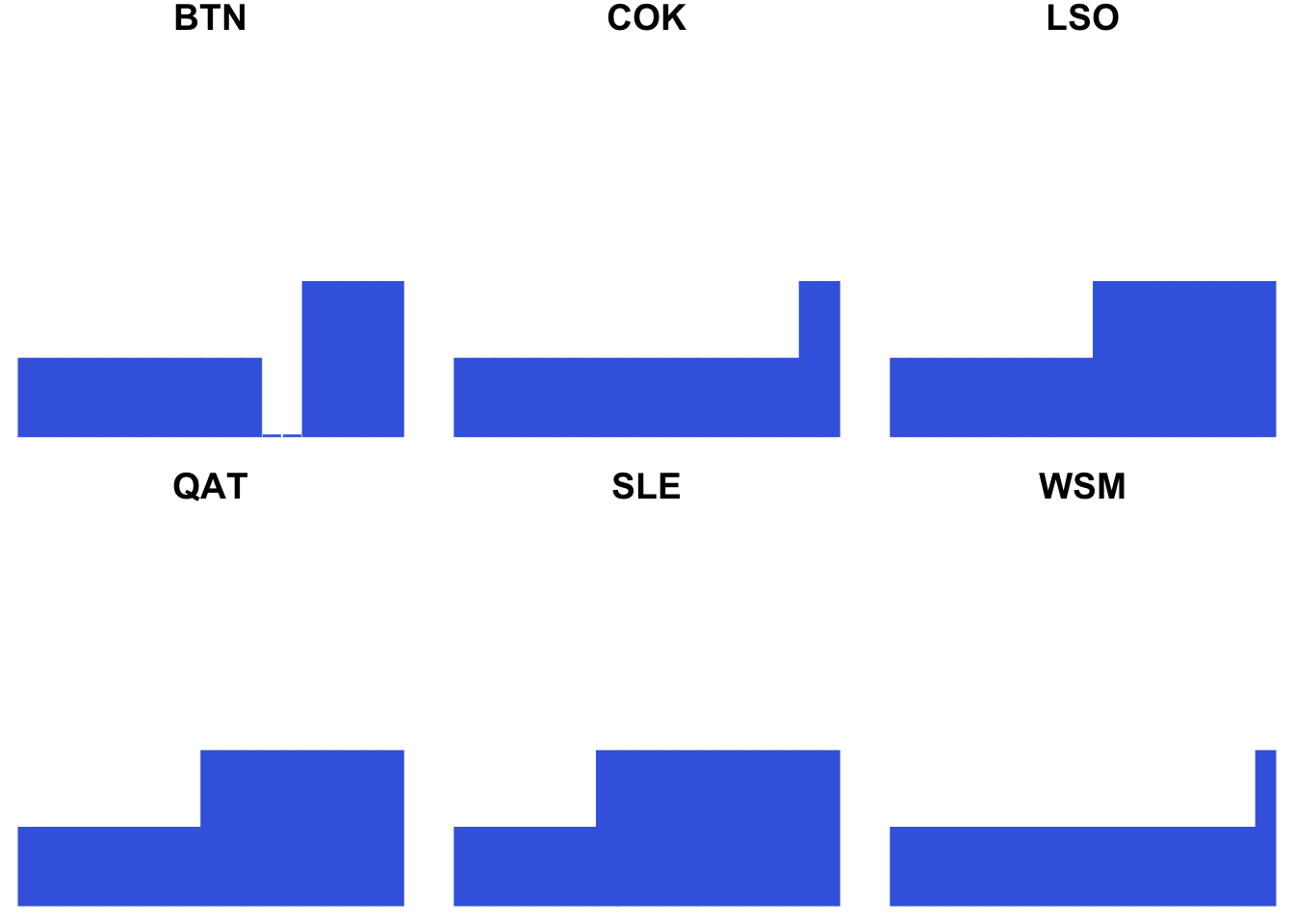
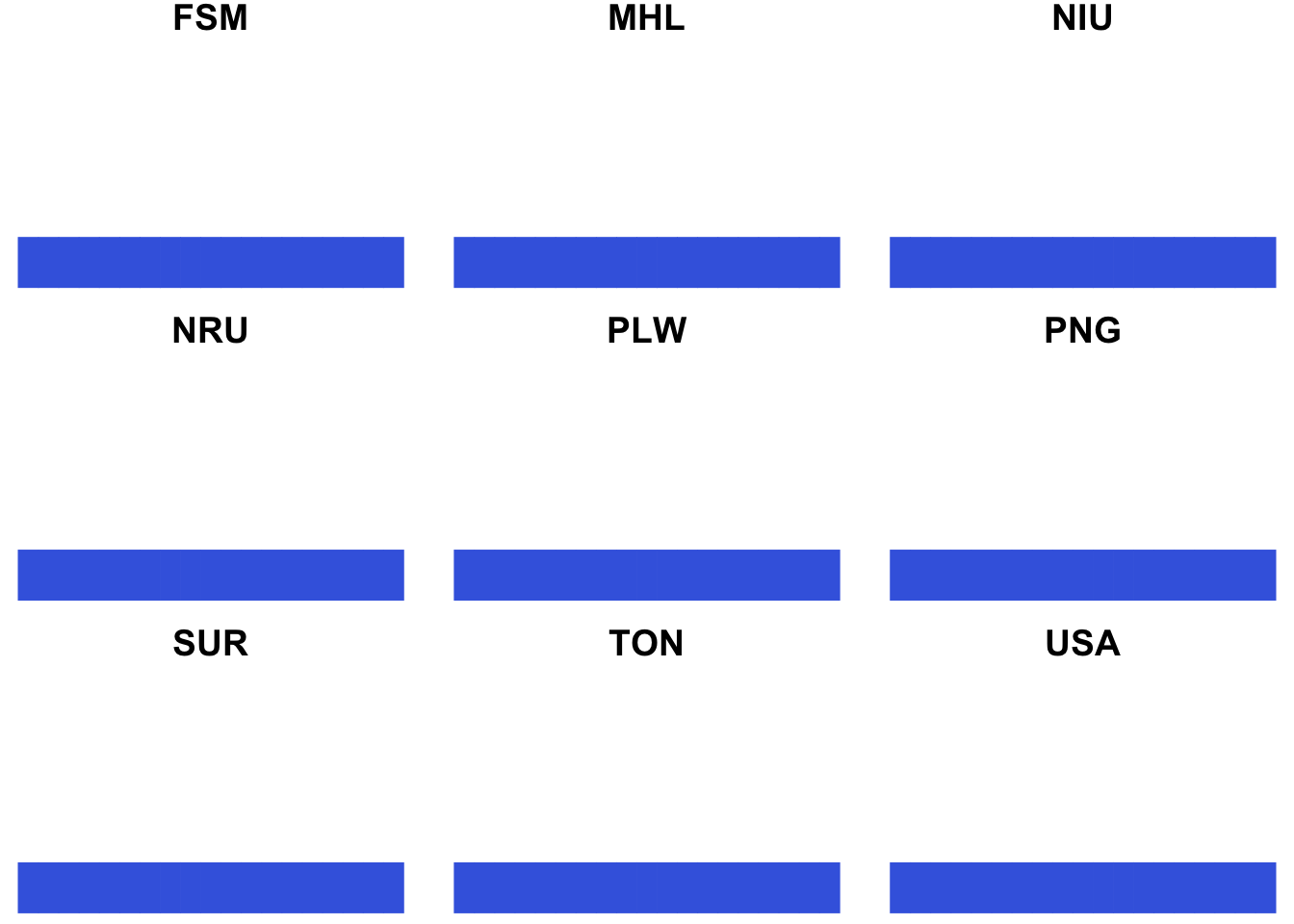
6.3.6 Gathering subplots by cowplot
這段程式碼的作用是將多個 ggplot2 圖形物件組合成一個網格,然後將這個網格圖形儲存為一個圖像文件。首先,這段程式碼定義了多個變數,如 plot_row1、plot_row2、plot_row3 等,每個變數都是一個網格圖形。這些變數通過 plot_grid() 函數來創建,這個函數可以將多個 ggplot2 圖形物件組合成一個網格。在 plot_grid() 函數中,可以設置 labels 參數來為每個子圖添加標籤。
然後,這些變數通過 plot_grid() 函數再次組合,形成一個更大的網格圖形。這裡使用 ncol = 1 參數將多個網格排列成一列。最後,使用 ggsave() 函數將這個網格圖形儲存為一個圖像文件。在這個例子中,圖像文件的名稱是 “test.png”,大小為 10 英寸 x 30 英寸,分辨率為 300 DPI。
總的來說,這段程式碼的作用是將多個 ggplot2 圖形物件組合成一個網格,並將這個網格圖形儲存為一個圖像文件。這樣做可以方便地進行圖像導出和共享,並且可以將多個圖形合併在一起進行比較和分析。
library(cowplot)
plot55 <- matleave %>% filter(matleave_13 == 5, matleave_95 == 5) %>% generating_plot()
plot05 <- matleave %>% filter(matleave_13 == 5, matleave_95 != 5) %>% generating_plot()
plot44 <- matleave %>% filter(matleave_13 == 4, matleave_95 == 4) %>% generating_plot()
plot04 <- matleave %>% filter(matleave_13 == 4, matleave_95 != 4) %>% generating_plot()
plot33 <- matleave %>% filter(matleave_13 == 3, matleave_95 == 3) %>% generating_plot()
plot03 <- matleave %>% filter(matleave_13 == 3, matleave_95 != 3) %>% generating_plot()
plot22 <- matleave %>% filter(matleave_13 == 2, matleave_95 == 2) %>% generating_plot()
plot02 <- matleave %>% filter(matleave_13 == 2, matleave_95 != 2) %>% generating_plot()
plot11 <- matleave %>% filter(matleave_13 == 1) %>% generating_plot()
plot_row1 <- plot_grid(plot55, plot05, labels = c('STAY 5', 'INCREASE TO 5'))
plot_row2 <- plot_grid(plot44, plot04, labels = c('STAY 4', 'INCREASE TO 4'))
plot_row3 <- plot_grid(plot33, plot03, labels = c('STAY 3', 'INCREASE TO 3'))
plot_row4 <- plot_grid(plot22, plot02, labels = c('STAY 2', 'INCREASE TO 2'))
final_plot <- plot_grid(
plot_row1, plot_row2, plot_row3, plot_row4, plot11,
ncol = 1
)
ggsave("test.png", final_plot, width=10, height=30, dpi=300)